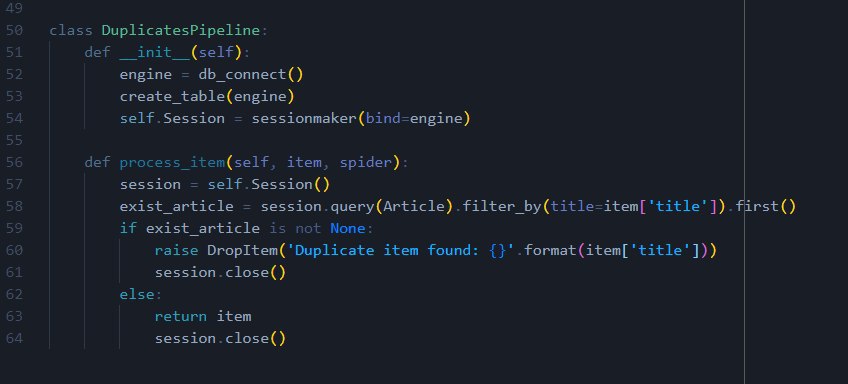
D
А бд нельзя прикрутить?
ну допустим вместо сохраненных ссылок в файл. они в БД, так иногда делал когда больше 10к ссылок. но это не помогает решить мою проблему. а проблема в том, как оптимально проверить на наличие новых записей, если на 1 странице только старые. а 2 странице могут быть новые. если на форуме(сайте/сервисе) дебильная система и все темы где отвечают юзеры, отображаются на 1 странице