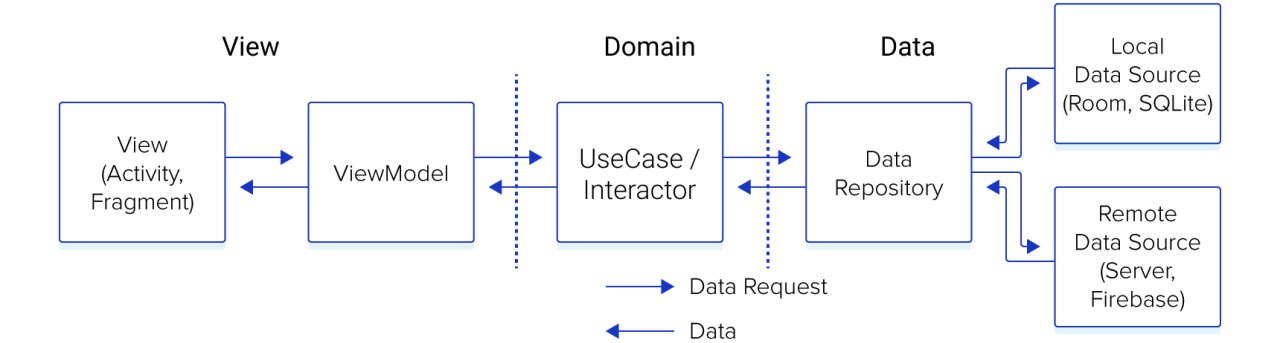
тогда будет что-то подобное
у репозитория А будет методы фетч1, фетч2
и надо будет сделать юз кейс, который будет дергать а.фетч1 и все
собственно зачем
если можно просто в юз кейсе с названием фетч1 сделать всю логику по обработке и сохранению, заинжектив туда базу данных и интерфейс апи
В вашем случае, юзкейс это тупая обёртка, которая ничего не делает, кроме как возврата результата с сервера\бд и тд.
Но как только появляется бизнес логика, всё усложняется и получится каша
Получается что в домейн слой втягиваются зависимости из дата слоя и смешивается бизнес-логика с логикой сохранения\кеширования данных (нарушение single responsibility), о чём домейн собственно даже не должен знать.
Вообще архитектура зависит от бизнес требований, так что ничто не мешает вам сделать по вашей схеме, но ничто так же не мешает в интерфейсе репозитория сделать метод который вернет данные из конкретного источника или пробросить какой-нибудь флаг
Всё это допустимые варианты