Александр
Вопрос с двумя звездочками: а в чем плюсы минусы и особенности azure, databricks и тд в этом же философском срезе?
Тут уже сугубое ИМХО. Биг дату в принципе можно обрабатывать как в классических SQL хранилищах, так и в вот в этом всем. Если данные норм структурированы то имхо лучше сразу строить нормальное ХД, MPP Субд (а если в 6НФ, то можно брать и не столь уж структурированные данные) норм справятся с любыми обьемами при грамотном проектировании. А если данные не структурированы, или проблемы с проектированием - то приходится крутить Apache Spark, Hadoop, и прочее. Такое ИМХО, тема не совсем моя.
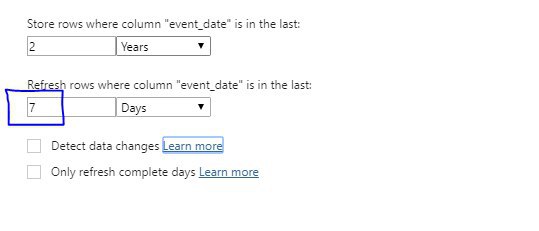
Выбрать между кубами MD или Tabular легко, просто делайте в том в чем умеете, результат в любом случае будет лучше, чем делать в том в чем не умеешь). Если навык одинаковый и там и там (0)), или просто смотрите на перспективу, то берите Tabular, он современный, он развивается, он инмемори, разрабатывать гора-аздо в нем проще и быстрей, и при этом результат не страдает, не надо заморачиваться с дизайном агрегаций и прочим. Язык DAX, имхо, более понятен чем MDX, есть оч. удобный инструмент DAX Studio, отладка запросов делается гораздо приятней чем в MDX, и DAX используется в SSAS и в PBI, плюс можно спихнуть часть разработки на аналитиков, тот же PBI позволят писать собственные меры при прямом подключении к Tab кубу. В целом связка PBI+Tabular богата на возможности - можно реализовать incremental update в кубе, без всяких PBI Premium. Tabular куб опять же многое прощает, но до определенного предела, потом все равно надо вникать в оптимизацию. И несмотря на ограниченность обьемами оперативной памяти и лицензией, запихнуть туда можно очень много, при грамотном проектировании, запихивают до десятков миллиардов строк в пределе.
Ссылки почитать.. да еще valuable.. читайте книжки итальянце в части моделирования SSAS Tabular, не ошибетесь )