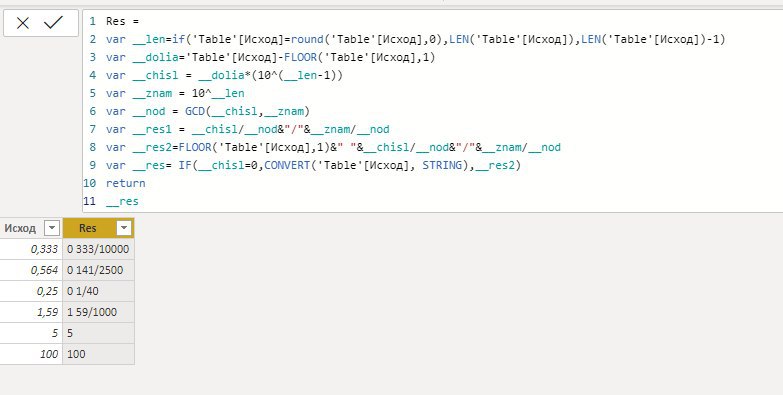
Чатик есть, но там зубры сидят.. с решениями немного другого порядка сложности.
Да, по крайней мере, pbi-чат очень активный, тут живое общение.
по поводу архитектуры
Я бы начал с малого и просто разделил данные, поступающие в PBI на 3 группы:
1. Сырые
2. Подготовленные кем-то
3. Подготовленные вами
Откуда они поступают - тоже вопрос, но для отдельного обсуждения.
Сырые данные - это плохо? Не всегда, конечно. Особенно в самом начале в маленькой задачке нет смысла заморачиваться о каких-то витринах и т.п. Так что берем сырые данные, причесываем в PQ и смело делаем отчёт. Чем больше у нас становится отчетов, тем больше мы тратим времени на то, чтобы данные причесать, значит тем больше возрастает необходимость в их предварительной обработке.
Подготовленные кем-то - это, вообще, как? А очень просто. Вы - аналитик, сотрудник большой компании. И не нужно забивать вам голову тем, как данные готовятся. Эскалируйте это на уровень ниже - пусть за вас этим занимается другой департамент/отдел. PQ тут стоит ипспользовать по минимуму, чтобы было однозначное понимание не только у вас, а у всех, с какими данными работает отчёт. Можно еще сюда добавить промежуточный этап - кубы, скажем, данные готовятся для вас где-то еще, а самим кубом управляете уже вы, только оттуда они попадают в отчёт, только там формируются меры.
Некому готовить данные? Не беда, сделаем это сами. Поднимем СУБД (любую - на вкус и цвет, как говорится) и приступим к созданию нашего маленького хранилища данных.
Тут любые средства хороши - начнём с ETL, соберем все, что нам нужно, в одном месте, потом создадим витрину для нашего отчёта (желательно по схеме звезда, чтобы все было понятно от одного взгляда на схему внутри отчёта), а дальше прицепимся к ней и (см. п.2.)
Но проблема в том, что СУБД великое множество, ETL - Тоже, тут, наверное, стоит обсуждать только какие-то хорошие архитектурные практики, не заморачиваясь на средствах.