Привет друзья! Подскажите, какой нынче самый лучший OCR движок для установки на сервак или сервис? Нужно побыстрому привинтить распознавание документов к нашим сервисам. В идеале хочется функционала что бы оно могло распознавать и заполнять паспортные данные
Всем привет! Нужно понять возможность спроектировать нейросеть для семантического анализа текста в отсканированных документах - в основном для поиска технических характеристик товаров. Вопросов сразу несколько:
Нужен ли сторонний OCR для всего документа или возможно будет сначала создать образы страниц (сплошной текст - мимо, нечто похожее на перечисление - распознаем)? Во что распознавать если работать с этим документом будет не человек? Какие решения (платформы) рассматривать как основные для реализации? Tensorflow, Caffe? Какой объем датасета и какого качества готовить? Какой, приблизительно, временной период может занять обучение на некоем примерном оборудовании?
Пойдем со мной, если хочешь.... хз, к туда где сейчас покажу. Мне нужно туда кого-то вкинуть, чтобы этим истеричкам напомнить личку «не тех, кто в контактах» почитать... а ты, заодно, 800 математиков увидишь в одном месте? М? М?
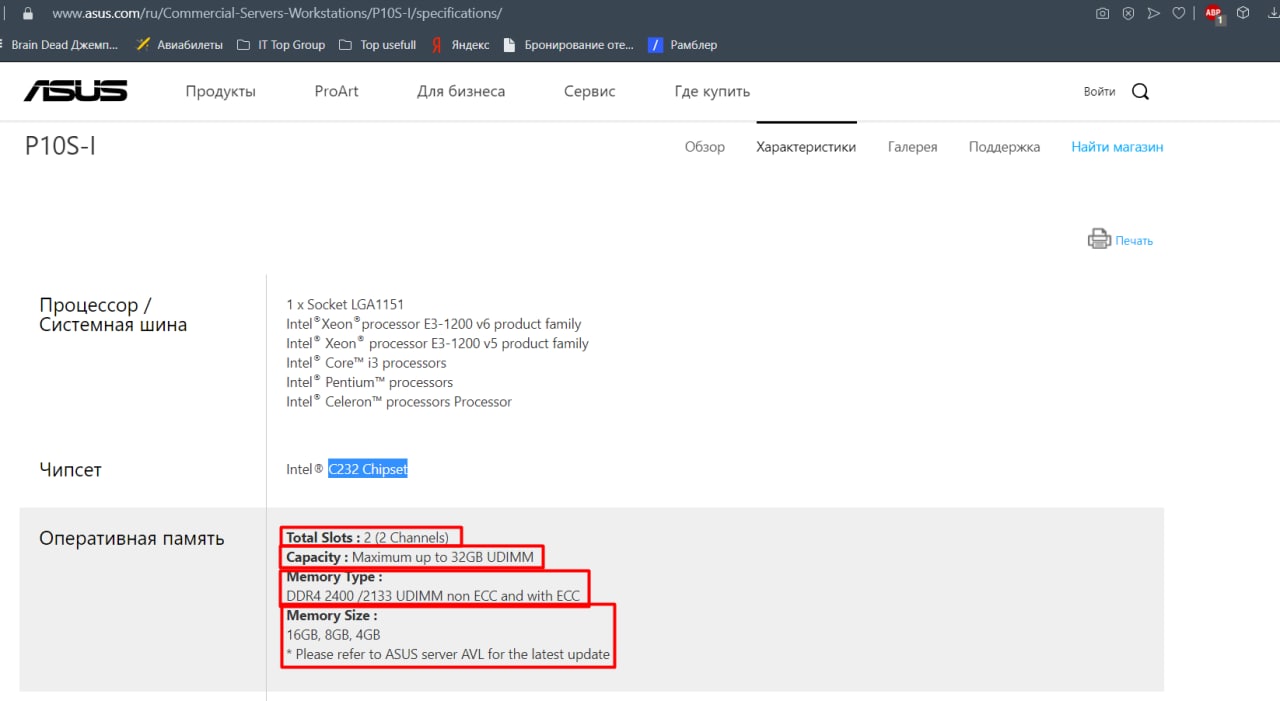
Народ, есть вопрос. Имеется материнка asus p10s-i, у которой в опиании max ram = 32gb. Хотя для нее же продается кит 64gb (2x32gb). При этом на офифциальном сайте и на форумах ничего не пишут. Может кто умеет узнать, поддерживает ли материнка 64гб оперативки ?