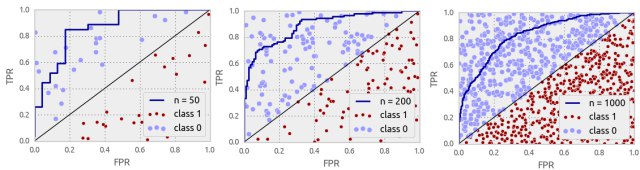
DC
Это я так понимаю для каждого класса отдельно?
Size: a a a
DC
СВ
СВ
DC
DC
DC
СВ
СВ
СВ
СВ
СВ
СВ
СВ
tensorflow.python.framework.errors_impl.NotFoundError: Failed to create a directory: C:\keras\Directory\models\temp_model/variables; No such file or directoryS
КЧ
BB
DD
S
DD