ДА
а ты расчитывал что оно будет писать на несколько дисков ожидая подтверждения от соседей со скоростью выше чем у отдельного диска?
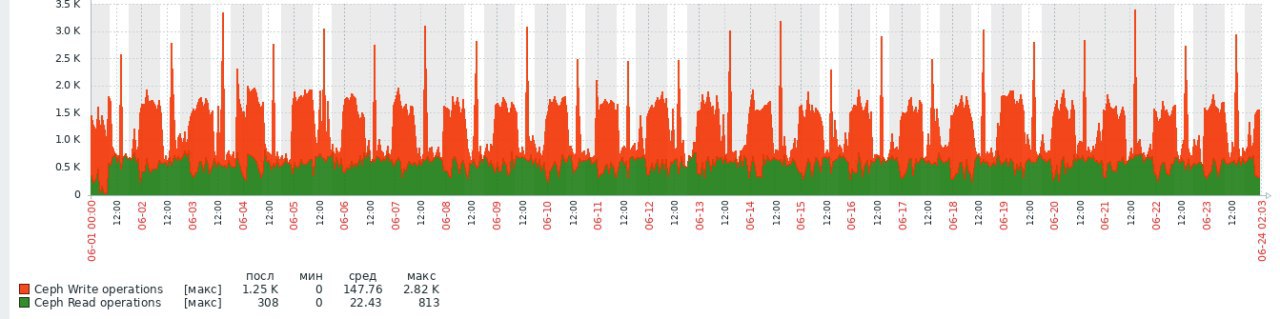
я не знаю как относиться к полученным результатам при тестировании большого количества ВМ, но прекрасно понимаю, что на момент тестирования кластера Red Hat(тесты проводились только на 1-2 ВМ, так как было не очень удобно через libvirt) ошибки slow ops, как правило, возникали в промежутках между тестами, вот в таких глупых случаях, когда уже как 10 минут все тесты прошли, а при попытке создать файловую систему, клиентская машина с диском РБД полностью виснит на протяжении 10-20-30 а иногда даже 40 минут