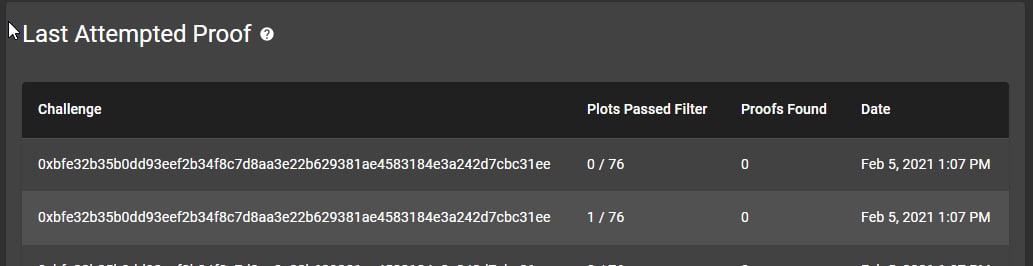
насколько я понимаю там сперва плотсы проходят фильтр, типа берется 1/256-я всех плотсов, а потом вычисляется у кого какой ответ на этот челлендж, у того у кого лучший - смайнил блок
в бурст данные тоже можно было рассортировать так, чтобы scoops 1-64 лежали на диске 1, 65-128 на диске 2 и т.д., но плоттеры этого не умели. Там в каждом плот файле лежали все 4096 скупс, поэтому читалось по кусочку каждого файла.