



DC
toUInt64() и возможно придется добавить intDiv в зависимости от хранимой точности
toUInt64 сделает только секунды
Size: a a a
DC
VB
DC
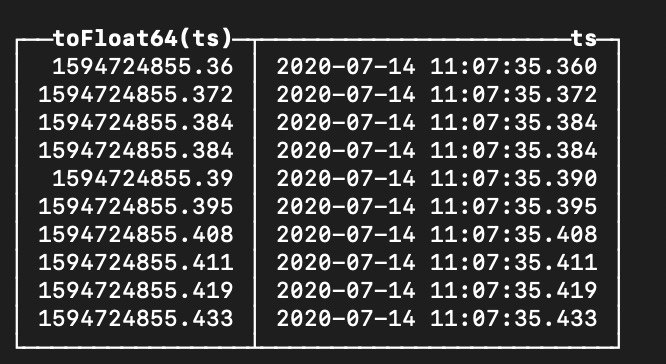
DateTime64 с точностью до миллисекундVB
VB
VB

DC
DT
DC
МШ
VB
DC
МШ
DC
МШ
DC
IZ
ClickHouse server version 19.8.3.8 (official build). <graphite_rollup>
<path_column_name>Path</path_column_name>
<time_column_name>Time</time_column_name>
<value_column_name>Value</value_column_name>
<version_column_name>Timestamp</version_column_name>
<default>
<function>avg</function>
<retention>
<age>0</age>
<precision>1</precision>
</retention>
<retention>
<age>86400</age>
<precision>60</precision>
</retention>
<retention>
<age>864000</age>
<precision>900</precision>
</retention>
<retention>
<age>1728000</age>
<precision>1800</precision>
</retention>
</default>
</graphite_rollup>
CREATE TABLE graphite (`Path` String, Value Float64, Time DateTime, Date Date, Timestamp UInt32) ENGINE = GraphiteMergeTree('graphite_rollup') PARTITION BY toYYYYMM(Date) ORDER BY (Path, Time) SETTINGS index_granularity = 8192SELECT *
FROM graphite
WHERE (Date = '2020-06-17') AND (Path = 'statsd.numStats')
ORDER BY Timestamp DESC
LIMIT 2
┌─Path────────────┬──────────Value─┬────────────────Time─┬───────Date─┬────Timestamp─┐
│ statsd.numStats │ 4 │ 2020-06-17 23:59:59 │ 2020-06-17 │ 1592427599 │
│ statsd.numStats │ 4 │ 2020-06-17 23:59:58 │ 2020-06-17 │ 1592427598 │
└─────────────────┴────────────────┴─────────────────────┴────────────┴──────────────┘
SELECT *
FROM graphite
WHERE (Date = '2020-06-16') AND (Path = 'statsd.numStats')
ORDER BY Timestamp DESC
LIMIT 2
┌─Path────────────┬──────────Value─┬────────────────Time─┬───────Date─┬────Timestamp─┐
│ statsd.numStats │ 4 │ 2020-06-16 23:59:00 │ 2020-06-16 │ 1592341199 │
│ statsd.numStats │ 4 │ 2020-06-16 23:58:00 │ 2020-06-16 │ 1592341139 │
└─────────────────┴────────────────┴─────────────────────┴────────────┴──────────────┘
## SET optimize_throw_if_noop = 1
## OPTIMIZE TABLE graphite PARTITION 202007 FINAL
Code: 388. DB::Exception: Received from localhost:6788, 127.0.0.1. DB::Exception: Insufficient available disk space, required 191.81 GB.
## OPTIMIZE TABLE graphite PARTITION 202006 FINAL
Code: 388. DB::Exception: Received from localhost:6788, 127.0.0.1. DB::Exception: Insufficient available disk space, required 124.50 GB.
SELECT
table,
sum(rows),
partition,
count() AS number_of_parts,
formatReadableSize(sum(bytes)) AS sum_size
FROM system.parts
WHERE table = 'graphite'
GROUP BY
table,
partition
ORDER BY partition ASC
┌────table─┬──────sum(rows)─┬─partition─┬─number_of_parts─┬─sum_size───┐
│ graphite │ 7171581973 │ 202006 │ 9 │ 57.98 GiB │
│ graphite │ 14093390942 │ 202007 │ 619 │ 89.65 GiB │
└──────────┴────────────────┴───────────┴─────────────────┴────────────┘
МШ
АФ
DC
ClickHouse server version 19.8.3.8 (official build). <graphite_rollup>
<path_column_name>Path</path_column_name>
<time_column_name>Time</time_column_name>
<value_column_name>Value</value_column_name>
<version_column_name>Timestamp</version_column_name>
<default>
<function>avg</function>
<retention>
<age>0</age>
<precision>1</precision>
</retention>
<retention>
<age>86400</age>
<precision>60</precision>
</retention>
<retention>
<age>864000</age>
<precision>900</precision>
</retention>
<retention>
<age>1728000</age>
<precision>1800</precision>
</retention>
</default>
</graphite_rollup>
CREATE TABLE graphite (`Path` String, Value Float64, Time DateTime, Date Date, Timestamp UInt32) ENGINE = GraphiteMergeTree('graphite_rollup') PARTITION BY toYYYYMM(Date) ORDER BY (Path, Time) SETTINGS index_granularity = 8192SELECT *
FROM graphite
WHERE (Date = '2020-06-17') AND (Path = 'statsd.numStats')
ORDER BY Timestamp DESC
LIMIT 2
┌─Path────────────┬──────────Value─┬────────────────Time─┬───────Date─┬────Timestamp─┐
│ statsd.numStats │ 4 │ 2020-06-17 23:59:59 │ 2020-06-17 │ 1592427599 │
│ statsd.numStats │ 4 │ 2020-06-17 23:59:58 │ 2020-06-17 │ 1592427598 │
└─────────────────┴────────────────┴─────────────────────┴────────────┴──────────────┘
SELECT *
FROM graphite
WHERE (Date = '2020-06-16') AND (Path = 'statsd.numStats')
ORDER BY Timestamp DESC
LIMIT 2
┌─Path────────────┬──────────Value─┬────────────────Time─┬───────Date─┬────Timestamp─┐
│ statsd.numStats │ 4 │ 2020-06-16 23:59:00 │ 2020-06-16 │ 1592341199 │
│ statsd.numStats │ 4 │ 2020-06-16 23:58:00 │ 2020-06-16 │ 1592341139 │
└─────────────────┴────────────────┴─────────────────────┴────────────┴──────────────┘
## SET optimize_throw_if_noop = 1
## OPTIMIZE TABLE graphite PARTITION 202007 FINAL
Code: 388. DB::Exception: Received from localhost:6788, 127.0.0.1. DB::Exception: Insufficient available disk space, required 191.81 GB.
## OPTIMIZE TABLE graphite PARTITION 202006 FINAL
Code: 388. DB::Exception: Received from localhost:6788, 127.0.0.1. DB::Exception: Insufficient available disk space, required 124.50 GB.
SELECT
table,
sum(rows),
partition,
count() AS number_of_parts,
formatReadableSize(sum(bytes)) AS sum_size
FROM system.parts
WHERE table = 'graphite'
GROUP BY
table,
partition
ORDER BY partition ASC
┌────table─┬──────sum(rows)─┬─partition─┬─number_of_parts─┬─sum_size───┐
│ graphite │ 7171581973 │ 202006 │ 9 │ 57.98 GiB │
│ graphite │ 14093390942 │ 202007 │ 619 │ 89.65 GiB │
└──────────┴────────────────┴───────────┴─────────────────┴────────────┘
<function>avg</function> -- считается неправильно, потому что это avg