



DG
ну и Distributed при ошибке повторяет insert до успеха, т.е. до бесконечности, и таким образом я видел как пользователи умудряются наплодить бесконечное кол-во дубликатов. Ну и трата CPU тоже.
Разумно. Что ж, пойду сделаю КТ ¯\_(ツ)_/¯
Size: a a a
DG
G
G
G
DC
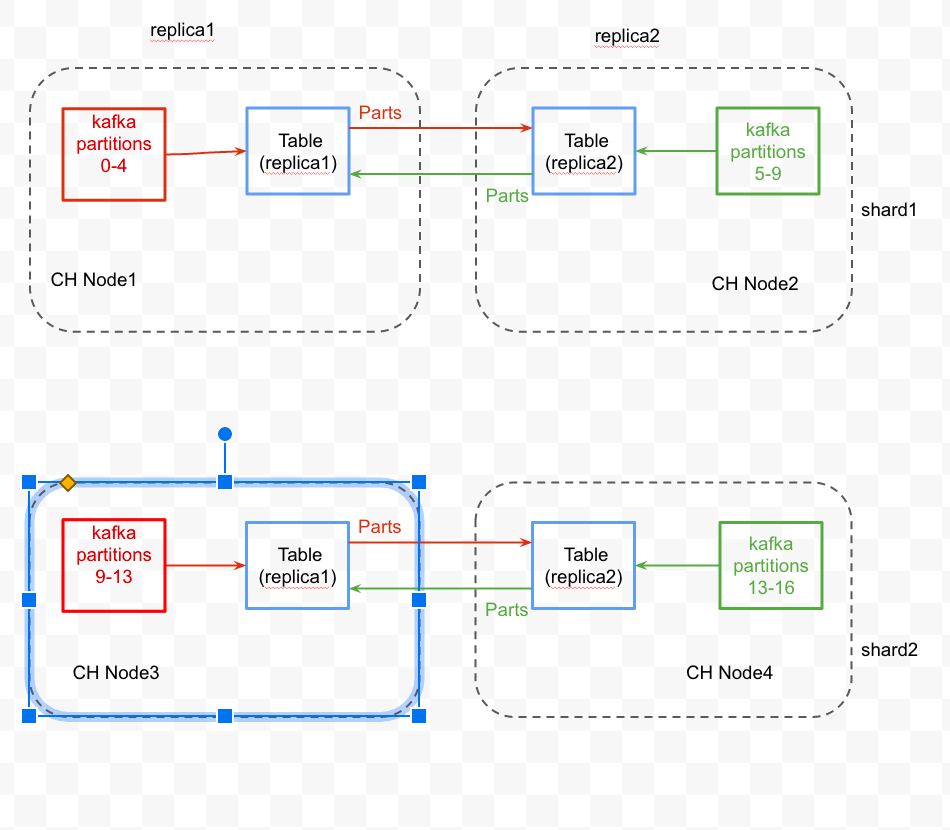
DC
G
G
DC
G
G
DC
G
G
G
DC
G
G
G
G