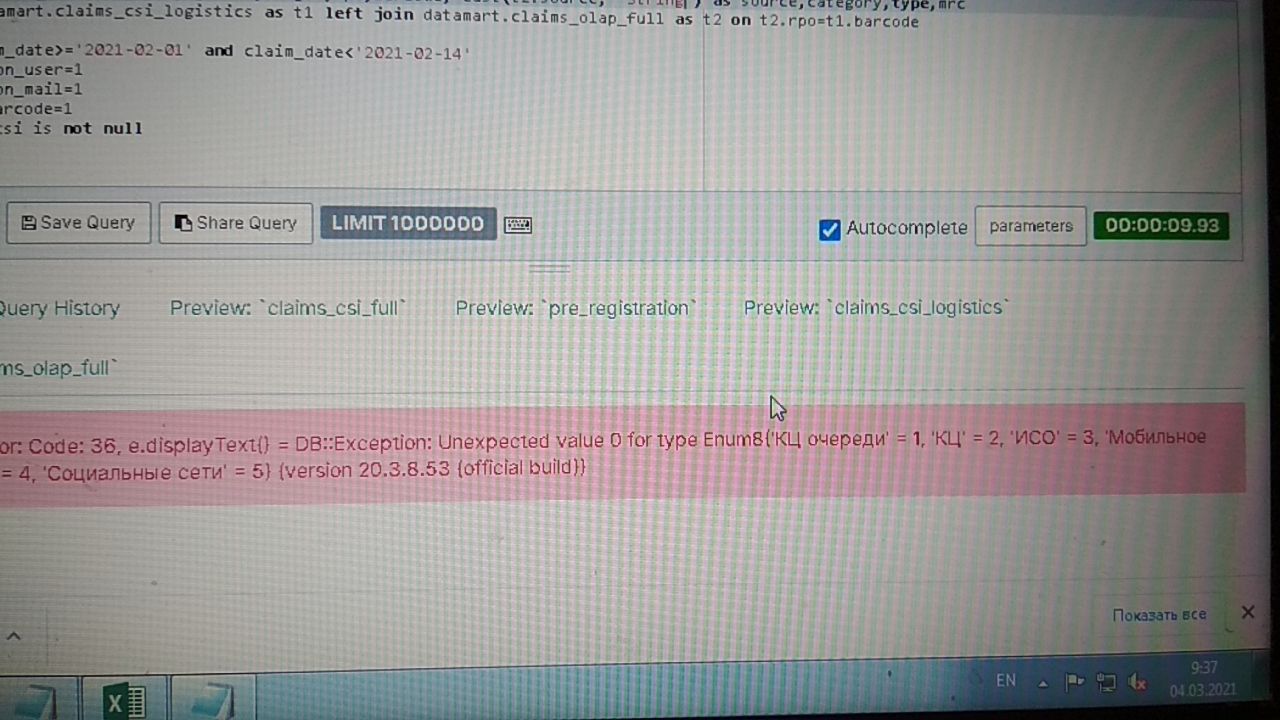
В КХ вы кладете 100МБ, он их еще 100 раз пережует и перезапишет, пока в итоге не сольется в 150ГБ.
Я посмотрел это выступление (кстати хорошее, есть важные моменты, не упомянутые в доках) и всё-таки не понимаю механизма, при котором хорошо прожеванные данные будут занимать больше места. Я бы наоборот ожидал что для каких-то кодеков отсортированные данные будут сжиматься лучше.