Не могли бы вы порекомендовать литературы по реализации инкрементальной проверки типов и вообще общей структуры реализации компилятора если я хочу сразу делать поддержку IDE/LSP.
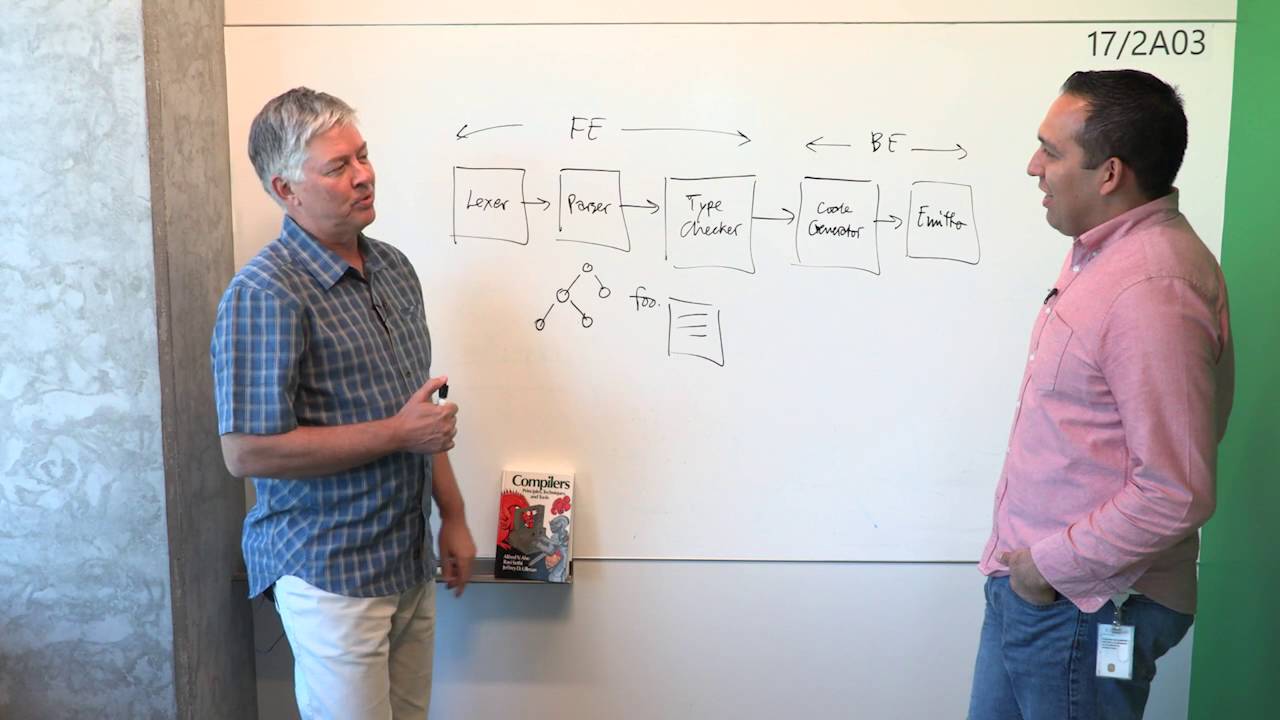
Я начал писать игрушечный язык, для того чтобы окончательно разобраться в том как все устроено (парсер/лексер/тайпчек/интерпретация/компиляция в х86/поддержка IDE), но я не совсем понимаю как лучше всего собственно реализовывать все. Из
https://www.youtube.com/watch?v=wSdV1M7n4gQ&t=1818s и
https://www.youtube.com/watch?v=74Y1n2v-gos&t=2106s я понял что большая часть принципов построения компиляторов слабо применима для работы IDE - в то время как при компиляции мы делаем полный проход по коду сверху вниз то для интерактивной работы мы фактически с нуля (с какими-то оптимизациями) собираем только нужную нам информацию.
Таким образом получается после CST/AST уже практически никаких схожих элементов нет, и фактически я пишу две разные программы, но может быть какие-то вещи которые я упустил.
И еще по поводу написания рекурсивного спуска -
https://news.ycombinator.com/item?id=13915150 - я правильно понимаю что в конечном итоге если я хочу делать компилятор и IDE то можно переиспользовать парсер, только добавил поддержку инкрементального разбора? И если да то как это лучше всего сделать - я посмотрел но не нашел ничего про то как добавить это (есть вещи типа "A simple and efficient incremental LL(1) parsing", но там про табличные парсеры). Кидаться в код каких-то промышленных компиляторов (типа rustc или roslyn) я пока еще не готов, особенно если стоит вопрос просто общего понимания принципов.
Про tree-sitter знаю, но хотелось бы все же не делать два разных AST без острой на то необходимости.