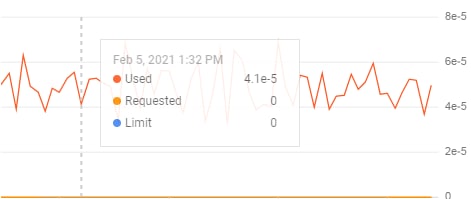
АМ
вот это ещё можно внимательно прочитать, возможно поможет BackendConfig
https://cloud.google.com/kubernetes-engine/docs/concepts/ingress#interpreted_hc
https://cloud.google.com/kubernetes-engine/docs/concepts/ingress#interpreted_hc
Size: a a a
АМ
ZO
S
AK
AK
S
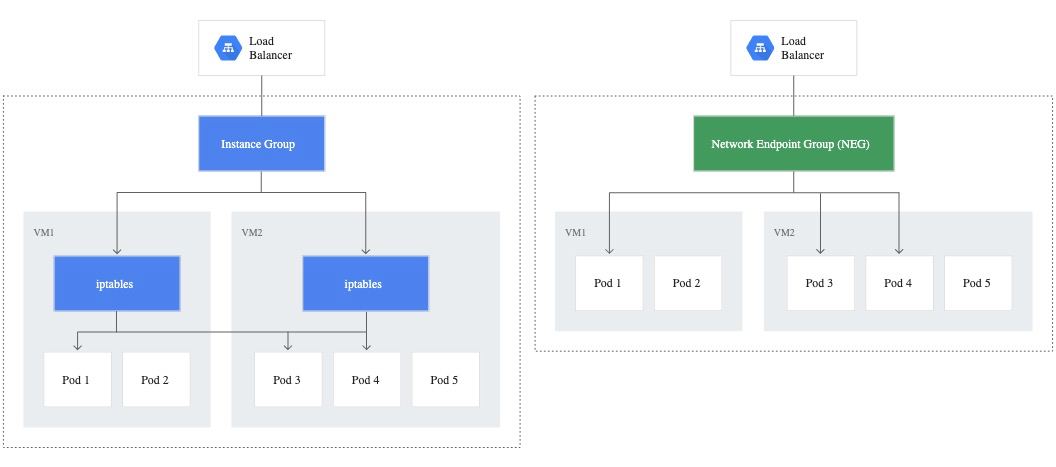
AK
S
readinessProbe:
failureThreshold: 3
httpGet:
path: /replicas_status
port: http
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
livenessProbe:
failureThreshold: 3
httpGet:
path: /ping
port: http
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
AK
readinessProbe:
failureThreshold: 3
httpGet:
path: /replicas_status
port: http
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
livenessProbe:
failureThreshold: 3
httpGet:
path: /ping
port: http
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
S
AK
am

am