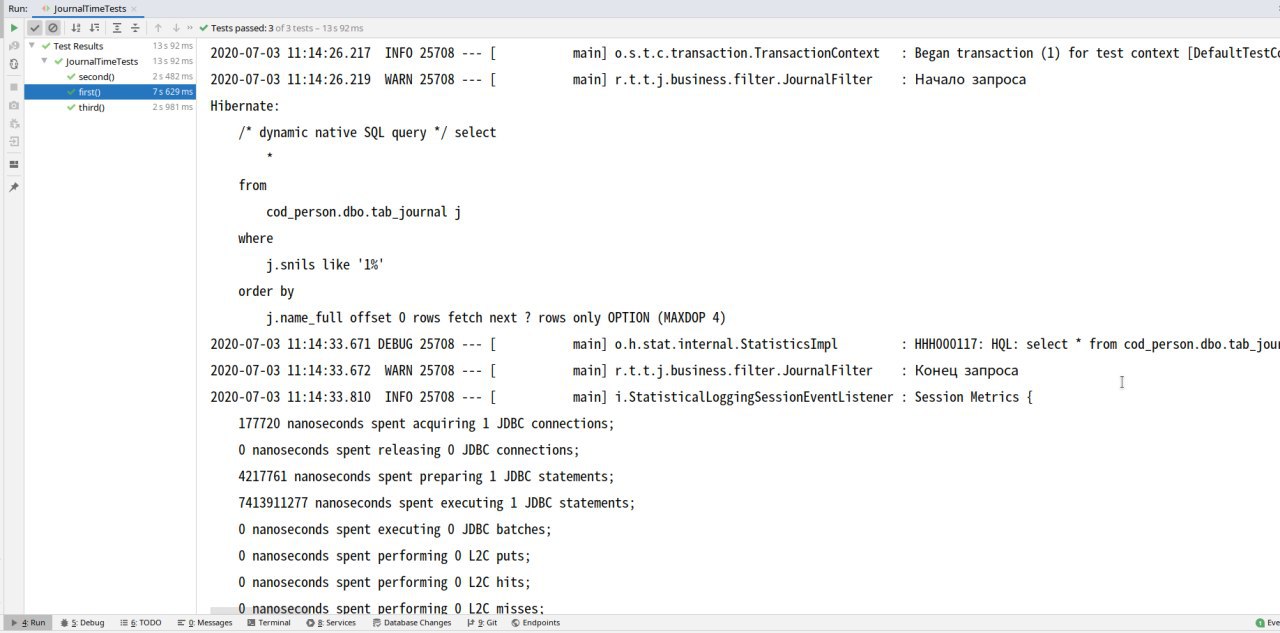
Ну и? В первом случае 6 сек с обрезкой в БД через SQL. Норм.
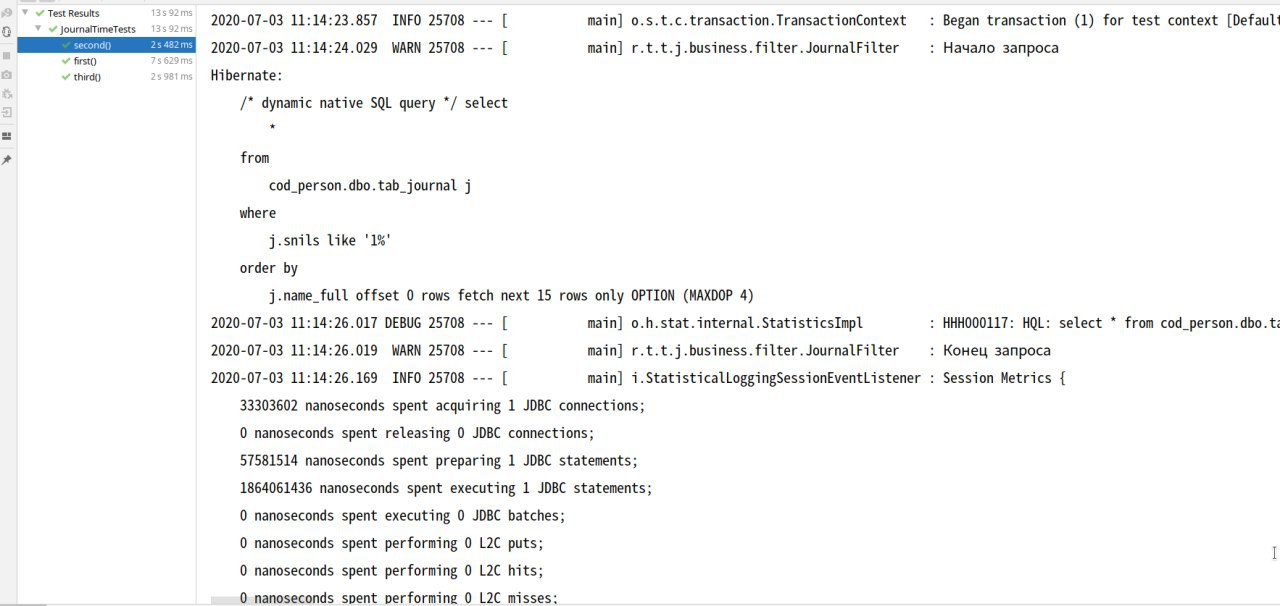
Во втором 36 сек с setFirstResult и setMaxResults.
Обратите внимание, что этот подход к получению общего количества результирующего набора требует дополнительного запроса (для count()).Короче, вместо 1 запроса на 15 строк в 1м случае, тут 2 запроса. Причем я не уверен, что в бд идет запрос на страницу 15 записей а не выполняется обрезка из курсора.
Хорошо бы профильтровать запросы к БД через средчтва Mysql или снифер sql. И заодно смотреть VisualVM на jvm, как растет память при вычитывании этим способом.
Если первый способ работает, его и надо использовать. Значит второй просто не для этих целей, для небольших табличек.
Используйте 1й способ с параметрами, да и всё:
Query query = JPA.em().createNativeQuery("select count(*) from truck t inner join box b where t.truck_id=b.truck_id and t.shipment_upc=:code"); query.setParameter("code", code);