DC
Энивэй, если тебе нужна помощь - пиши конкретные вопросы
Size: a a a
DC
ДБ
" " на \\s+
2. Так как наш новый regex превысил в длину один символ (и собственно является полноценным регулярным выражением), то split() будет компилировать из него объект Pattern при каждом вызове, что является весьма дорогостоящей операцией. Поэтому можно вынести компиляцию Pattern в static контекст, чтобы она происходила только один раз;split в пользу ссылки на метод toCharArray
Итоговый вариант может выглядеть так: private static final Pattern DELIMITER_PATTERN = Pattern.compile("\\s+");
public static void main(String[] args) {
final String test = "eat sleep rave\ts repeat";
final List<char[]> result = getSplitWords(test);
result.forEach(chars -> System.out.println(Arrays.toString(chars)));
}
public static List<char[]> getSplitWords(String stringToSplit) {
return DELIMITER_PATTERN.splitAsStream(stringToSplit)
.map(String::toCharArray).collect(Collectors.toUnmodifiableList());
}K
ДБ
ZE
АБ
АБ
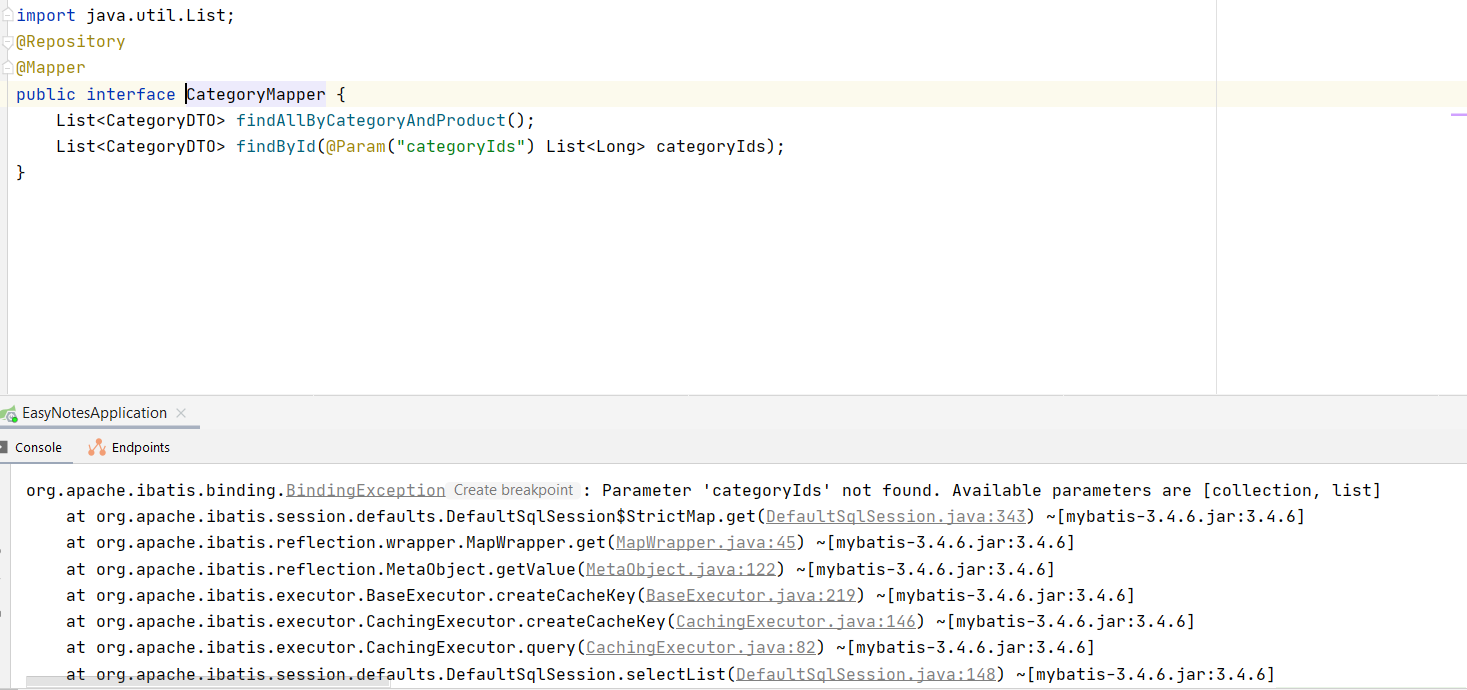
@ParamZE
@ParamАБ
findAllById(Iterable<> ids)
Если у тебя не используется в проекте JpaRepository, то больше ничем не могу помочь, у меня лапки)ZE
findAllById(Iterable<> ids)
Если у тебя не используется в проекте JpaRepository, то больше ничем не могу помочь, у меня лапки)ZE
ES
АБ
ES
LP
LP
LP
LP
LP