EB
Обязательно!
Спасибо!)
Size: a a a
EB
О
О
dp
DK
IT
SK
IT
AP
DK
DK
DK
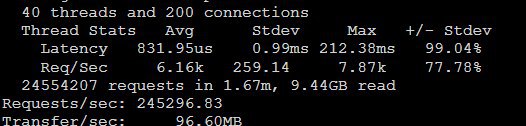
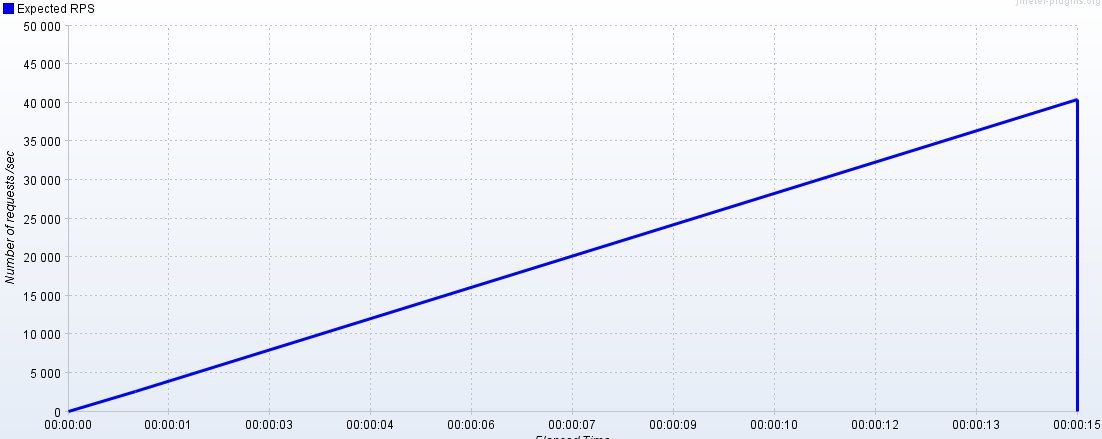
RPS * <max response time> / 1000, но c шейпинг-таймером не всё так просто, при увеличении входящей интенсивности будет расти время ответа, а соответственно максимальное время ответа, т.е. на таком профиле в любом случае нагрузка не будет подаваться линейно, а будет выходить на некоторое подобие насыщения.
S
RPS * <max response time> / 1000, но c шейпинг-таймером не всё так просто, при увеличении входящей интенсивности будет расти время ответа, а соответственно максимальное время ответа, т.е. на таком профиле в любом случае нагрузка не будет подаваться линейно, а будет выходить на некоторое подобие насыщения.
DK