Nikolay
Эта картинка пытливого наблюдателя скорее вводит в заблуждение.
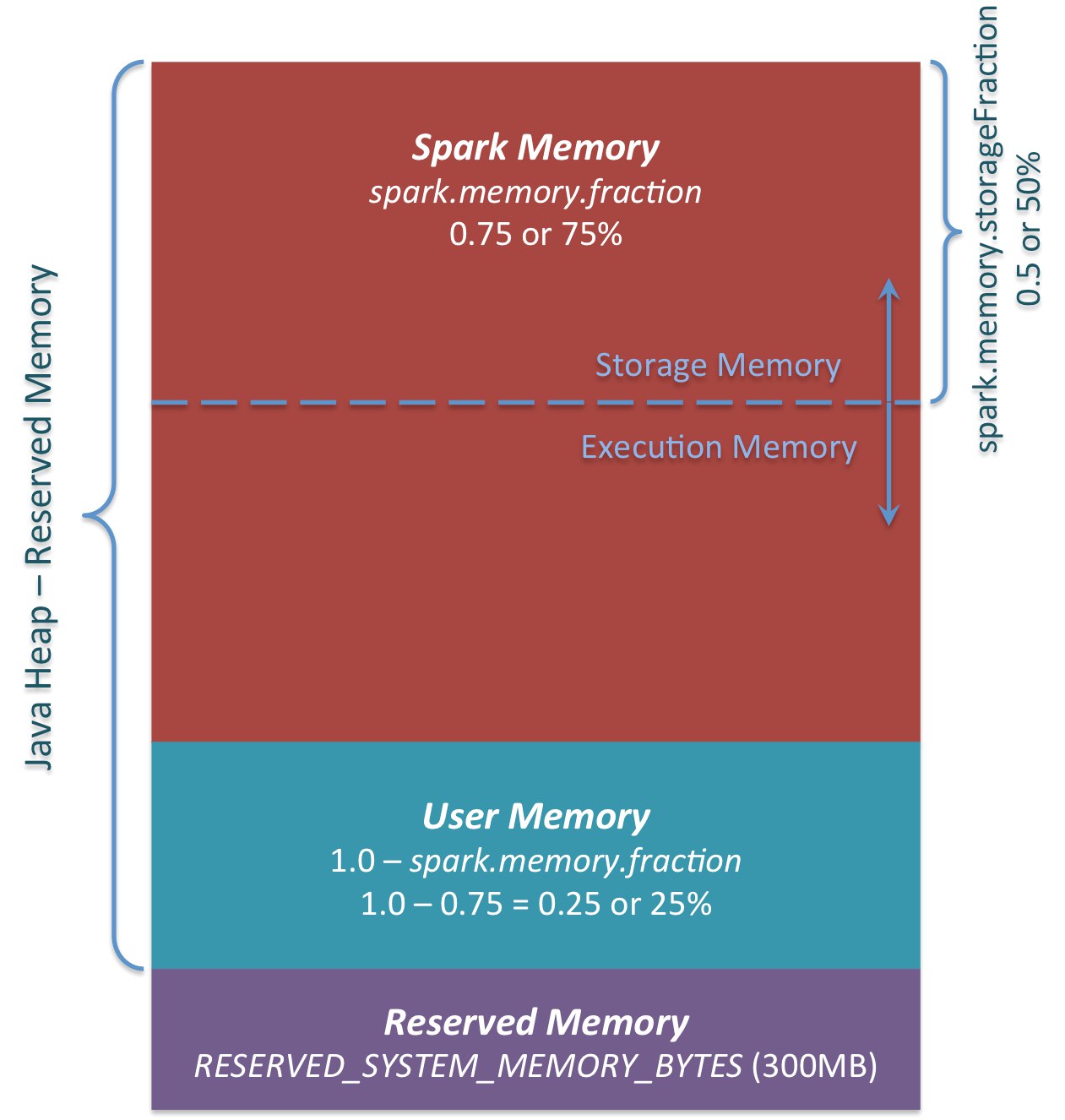
Глядя на нее можно сделать предположение, что память выделяется для каждой области непрерывными диапазонами. Это конечно не так. Спарк не отслеживает никакие диапазоны адрессов потому, что он на JVM. Он отслеживает размер, но и то не всегда, а только когда может. А может он только тогда, когда сам и трэкает это. Т.е пользователь своим обьектом может скушать всю память в спарке вообще, но когда спарк сам запрашивает себе память для хранения итератора в памяти или выполнения группировки, то он проверит сколько он уже взял для этого и не даст больше лимитов.
Т.е работает это примерно так. Есть память под хип. скажем 1G(systemMemory).Он будет считать, что 300mb(reservedMemory) всегда зарезервированно - set aside a fixed amount of memory for non-storage, non-execution purposes. А для мемори менеджера(фактически для execution и storage) доступно тогда (systemMemory - reservedMemory)*spark.memory.fraction (1024-300)*0.6 =434 mb. А для пользовательских обьектов 289 mb соответствено. Но пользователь может забрать при этом всю память, которая есть потому, что нет способа ограничить создание "пользовательских" обьектов
на JVM.
Меня этот вопрос, получается, интересовал применительно к spark.memory.fraction - насколько целесообразно такой большой объем выделять для пользовательских объектов, почти половина ресурсов? Наверное, конечно, неспроста в более поздних версиях коэффициент по умолчанию стал больше на 0.15, но все таки. Или тут такая же история, как и с execution/storage memory, и свободную память экзекутор при необходимости съест?