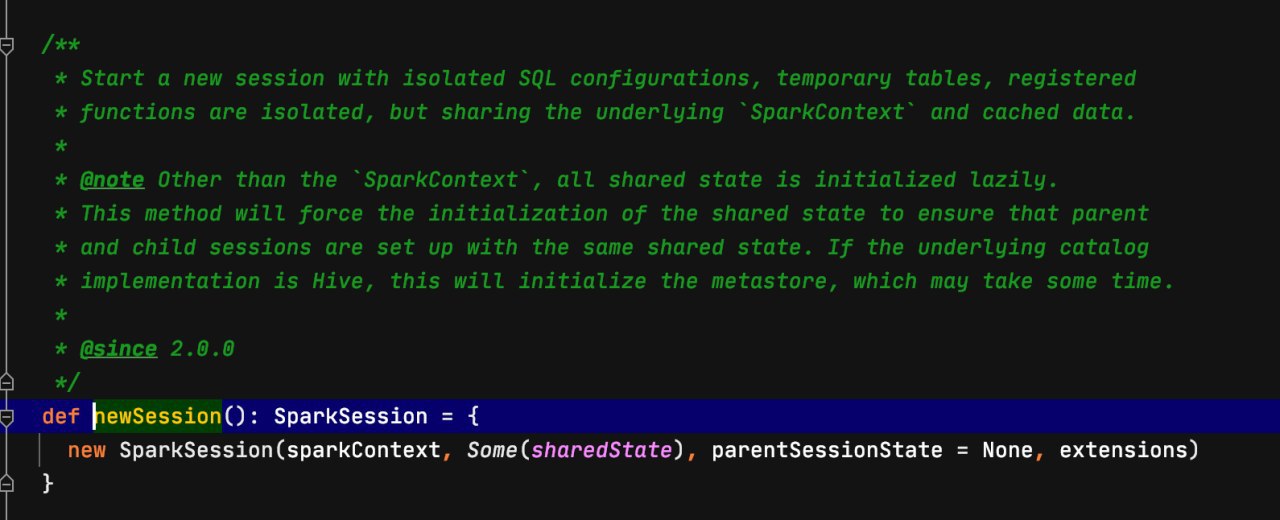
Всем привет!
Поясните такую ситуацию: spark 2.2 записывает датафрейм в паркет в HDFS с партиционирование по одному из полей.
Затем это же приложение начинает обрабатывать записанный датафрейм по партициям, читая каждую отдельно. Но иногда (не всегда) падает с ошибкой, потому что через некоторое время не может найти файл. Файлы в партициях есть, но UUID в их названиях не такой, как spark ожидает. Время создания файлов - намного позже, чем они были записаны изначально, по есть, в логе запись об окончании первого этапа в 5:00, файл записан в 6:00,а падение произошло в 6:30.
После перезапуска все норм, воспроизвести ошибку под контролем не удаётся.
Возможно ли, что UUID был изменен самим спарком в том же приложении? И как это предотвратить?