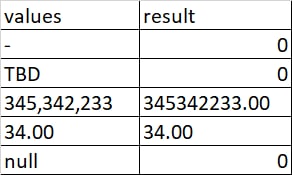
ИК
@KaiNie_R я правильно понимаю же?
да, если алгоритм это умеет и инкремент и run схлопнуть и это действительно нужно. Если инкремент каждый раз непредсказуемый, то run выйдет дороже, чем просто дельта по каждой строке. Но в идеале, да, 100500 миллионов единиц уложатся в несколько байт