



ПФ
Size: a a a
2021 March 21
2021 March 22
V
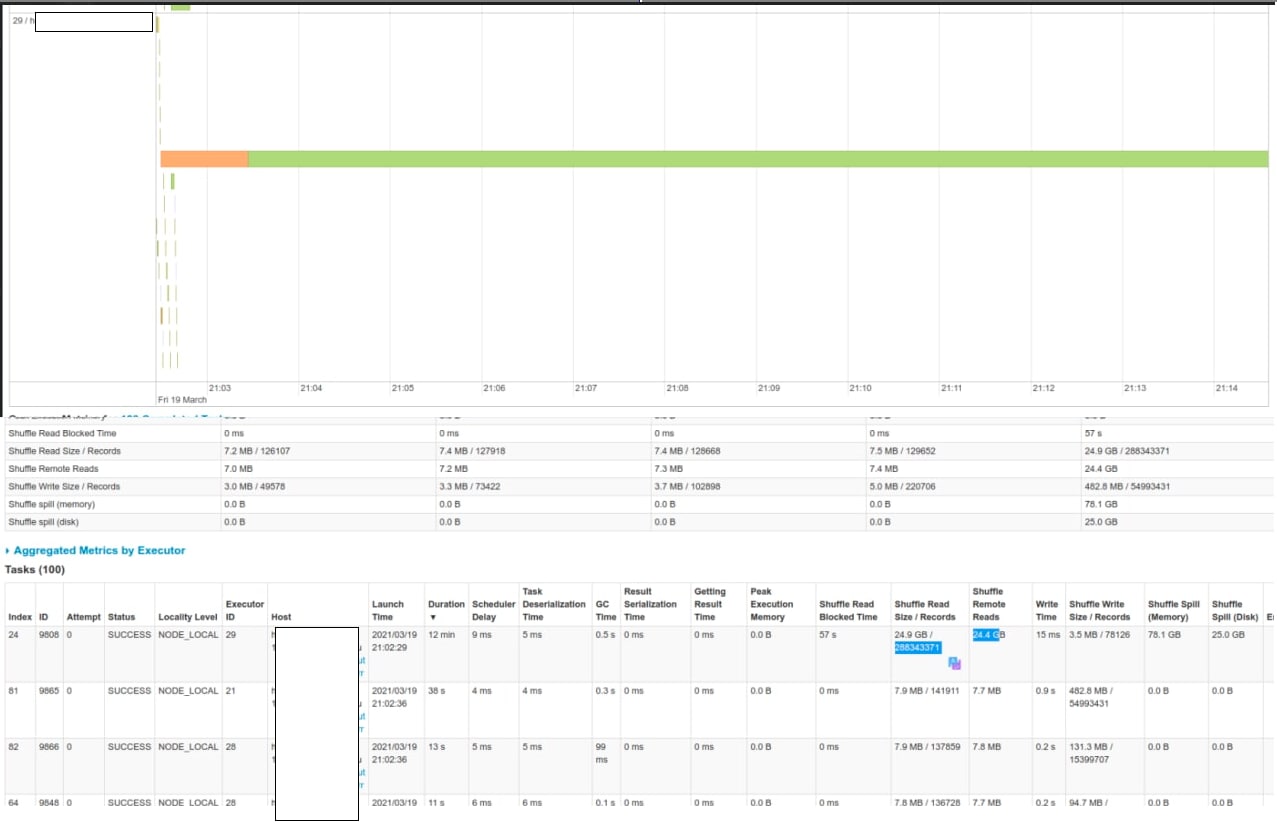
Привет всем. Подскажите плз - как вы определяете какой из десятка джоинов, которые есть в расчете, делают вот такое?
ПФ
Привет всем. Подскажите плз - как вы определяете какой из десятка джоинов, которые есть в расчете, делают вот такое?
В sql вью можно же смотреть за тем, скоро данных отсылается
V
Проблема в том, что экзекюторов 50 штук, а по факту работает один на который прилетает 25 гигов. В SQL view этого не понять. У меня несколько джоинов где примерно такой же объем данных.
N
Проблема в том, что экзекюторов 50 штук, а по факту работает один на который прилетает 25 гигов. В SQL view этого не понять. У меня несколько джоинов где примерно такой же объем данных.
посмотри распределения по ключам каждого джойна
AS
Привет всем. Подскажите плз - как вы определяете какой из десятка джоинов, которые есть в расчете, делают вот такое?
Я ничего лучше не нашел, чем после каждой агрегации вызывать action, что бы понимать что конкретно происходит на каждом этапе.
A
Я ничего лучше не нашел, чем после каждой агрегации вызывать action, что бы понимать что конкретно происходит на каждом этапе.
к сожалению так же делаю способа другого пока нету(
ПФ
к сожалению так же делаю способа другого пока нету(
Ждём обсерверов, видимо
V
Я ничего лучше не нашел, чем после каждой агрегации вызывать action, что бы понимать что конкретно происходит на каждом этапе.
Да, решил тоже так делать. Пишу результат джойна в паркет-файл и смотрю он это или нет.
A
Ждём обсерверов, видимо
есть ссылки почитать про это?
ПФ
De facto new data quality measuring tool is coming to the core @ApacheSpark
#dq #monitoring #dataquality
http://apache-spark-developers-list.1001551.n3.nabble.com/Observable-Metrics-on-Spark-Datasets-td30953.html
#dq #monitoring #dataquality
http://apache-spark-developers-list.1001551.n3.nabble.com/Observable-Metrics-on-Spark-Datasets-td30953.html
V
Коллеги, привет!
Посоветуйте плиз, как можно наиболее эффективным образом загрузить таблицу из Hive в Green Plum размером в 10Гб Spark-ом?
Возник кейс, что стандартный механизм загрузки через метод write с jdbc-подключением + указанием конфига на numPartitions (5) и batchsize = ‘1000000’ приводит к тому, что джоба забила логи в Green Plum однострочными insert и почти положила сервак из-за этого, хотя планировалось загружать батчами по 1000000 строк.
Мб кто-то решал такую проблему и может посоветовать что-то?
Посоветуйте плиз, как можно наиболее эффективным образом загрузить таблицу из Hive в Green Plum размером в 10Гб Spark-ом?
Возник кейс, что стандартный механизм загрузки через метод write с jdbc-подключением + указанием конфига на numPartitions (5) и batchsize = ‘1000000’ приводит к тому, что джоба забила логи в Green Plum однострочными insert и почти положила сервак из-за этого, хотя планировалось загружать батчами по 1000000 строк.
Мб кто-то решал такую проблему и может посоветовать что-то?
EC
Коллеги, привет!
Посоветуйте плиз, как можно наиболее эффективным образом загрузить таблицу из Hive в Green Plum размером в 10Гб Spark-ом?
Возник кейс, что стандартный механизм загрузки через метод write с jdbc-подключением + указанием конфига на numPartitions (5) и batchsize = ‘1000000’ приводит к тому, что джоба забила логи в Green Plum однострочными insert и почти положила сервак из-за этого, хотя планировалось загружать батчами по 1000000 строк.
Мб кто-то решал такую проблему и может посоветовать что-то?
Посоветуйте плиз, как можно наиболее эффективным образом загрузить таблицу из Hive в Green Plum размером в 10Гб Spark-ом?
Возник кейс, что стандартный механизм загрузки через метод write с jdbc-подключением + указанием конфига на numPartitions (5) и batchsize = ‘1000000’ приводит к тому, что джоба забила логи в Green Plum однострочными insert и почти положила сервак из-за этого, хотя планировалось загружать батчами по 1000000 строк.
Мб кто-то решал такую проблему и может посоветовать что-то?
Да
EC
Через pxf делаешь копию, потом exchange partitions
EC
Коллеги, привет!
Посоветуйте плиз, как можно наиболее эффективным образом загрузить таблицу из Hive в Green Plum размером в 10Гб Spark-ом?
Возник кейс, что стандартный механизм загрузки через метод write с jdbc-подключением + указанием конфига на numPartitions (5) и batchsize = ‘1000000’ приводит к тому, что джоба забила логи в Green Plum однострочными insert и почти положила сервак из-за этого, хотя планировалось загружать батчами по 1000000 строк.
Мб кто-то решал такую проблему и может посоветовать что-то?
Посоветуйте плиз, как можно наиболее эффективным образом загрузить таблицу из Hive в Green Plum размером в 10Гб Spark-ом?
Возник кейс, что стандартный механизм загрузки через метод write с jdbc-подключением + указанием конфига на numPartitions (5) и batchsize = ‘1000000’ приводит к тому, что джоба забила логи в Green Plum однострочными insert и почти положила сервак из-за этого, хотя планировалось загружать батчами по 1000000 строк.
Мб кто-то решал такую проблему и может посоветовать что-то?
Jdbc для mpp нифига не стандарт
EC
К слову пришлось )
V
Eugene Chipizubov
Через pxf делаешь копию, потом exchange partitions
ок, пойду гуглить, спасибо
V
Eugene Chipizubov
Через pxf делаешь копию, потом exchange partitions
А кроме как через external table есть варианты?
Этот вариант заказчику не подходит, требуется загрузить и создать физическую таблицу.
Этот вариант заказчику не подходит, требуется загрузить и создать физическую таблицу.
EC
Самый шустрый вариант это psql copy
EC
Ваш объем загрузит минуты за три в зависимости от нагрузки на мастер.