VS
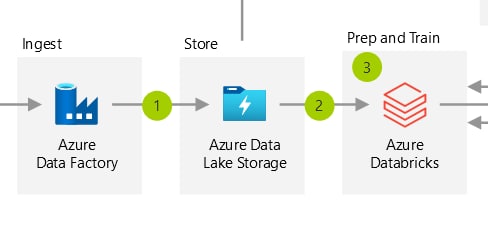
Тут помогает процедурный подход
Каждый блок это 1 преобразование который порождает новую таблицу
А dataflow решается через airfow
Каждый блок это 1 преобразование который порождает новую таблицу
А dataflow решается через airfow
ровно так мы и планировали поступить, правда для dataflow использовать meltano от gitlab, который из коробки включает dbt и airflow, но взвесив за и против, решили, что гибкости спарка все равно в таком подходе не достичь, т.к. нет четкого разделения данных и логики, в свою очередь нет возможности реализовать логику с помощью классических средств разработки (дебага, эксепшенов, профайлинга), нет возможности использовать функциональный подход, соответственно нет нормального тестирования, даже нет возможности провесить логами внутренности шага