



DT
Как перевести это на спарковый?
Size: a a a
DT
DT
N
C
DT
ММ
N
DT
DT
EC
EC
EC
P
АБ
IS
P
N
ММ
P
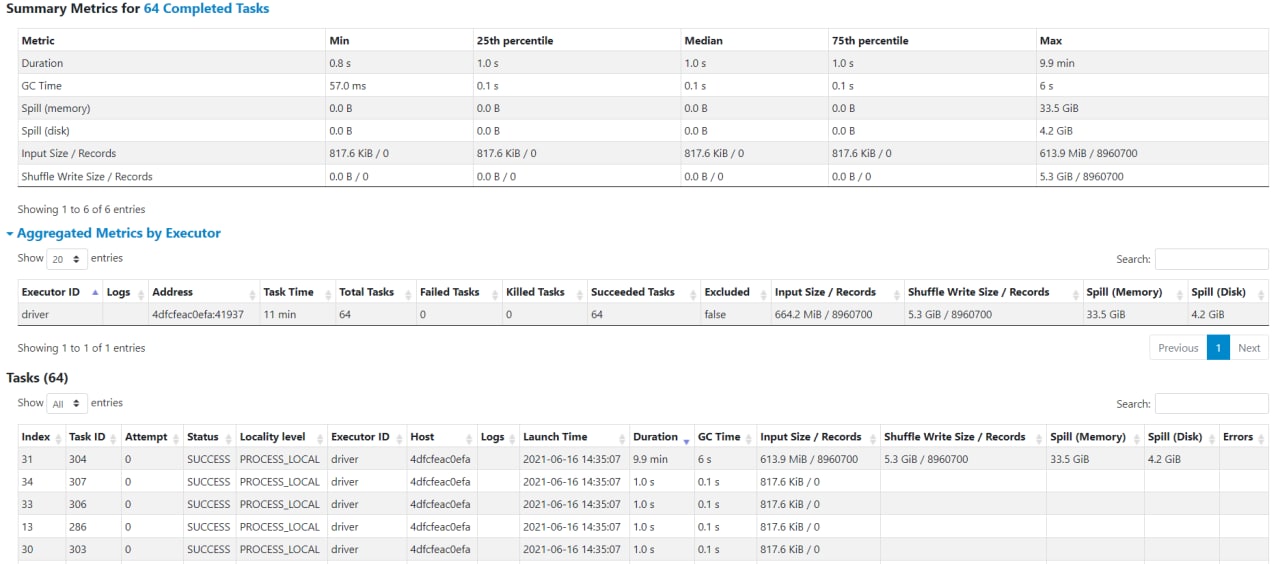
+-----------+-------+Если добавляю repartition(8), то 8 пратиций по равному кол-ву записей
|partitionId| count|
+-----------+-------+
| 31|8960700|
+-----------+-------+
+-----------+-------+Но при любом из вариантов все выполняется в одной таске.
|partitionId| count|
+-----------+-------+
| 4|1120087|
| 5|1120087|
| 3|1120087|
| 2|1120087|
| 6|1120088|
| 0|1120088|
| 1|1120088|
| 7|1120088|
+-----------+-------+
ИК