TM
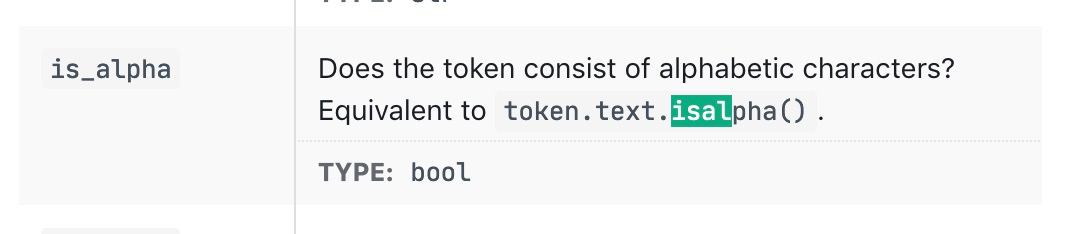
Ребята, какой наиболее универсальных подход к чистке контекста от не цифр и от небуквенных символов? В стеке SpaCy, подумали о проверке через
token.is_alphaно это выкинет и токены с цифрами. Грубо говоря нужно убивать
'1ый!$#& переулок д!!!!2%', но не
'1ый переулок д2'пусть пример вас не смущает, в нашей задаче это не NER'ы