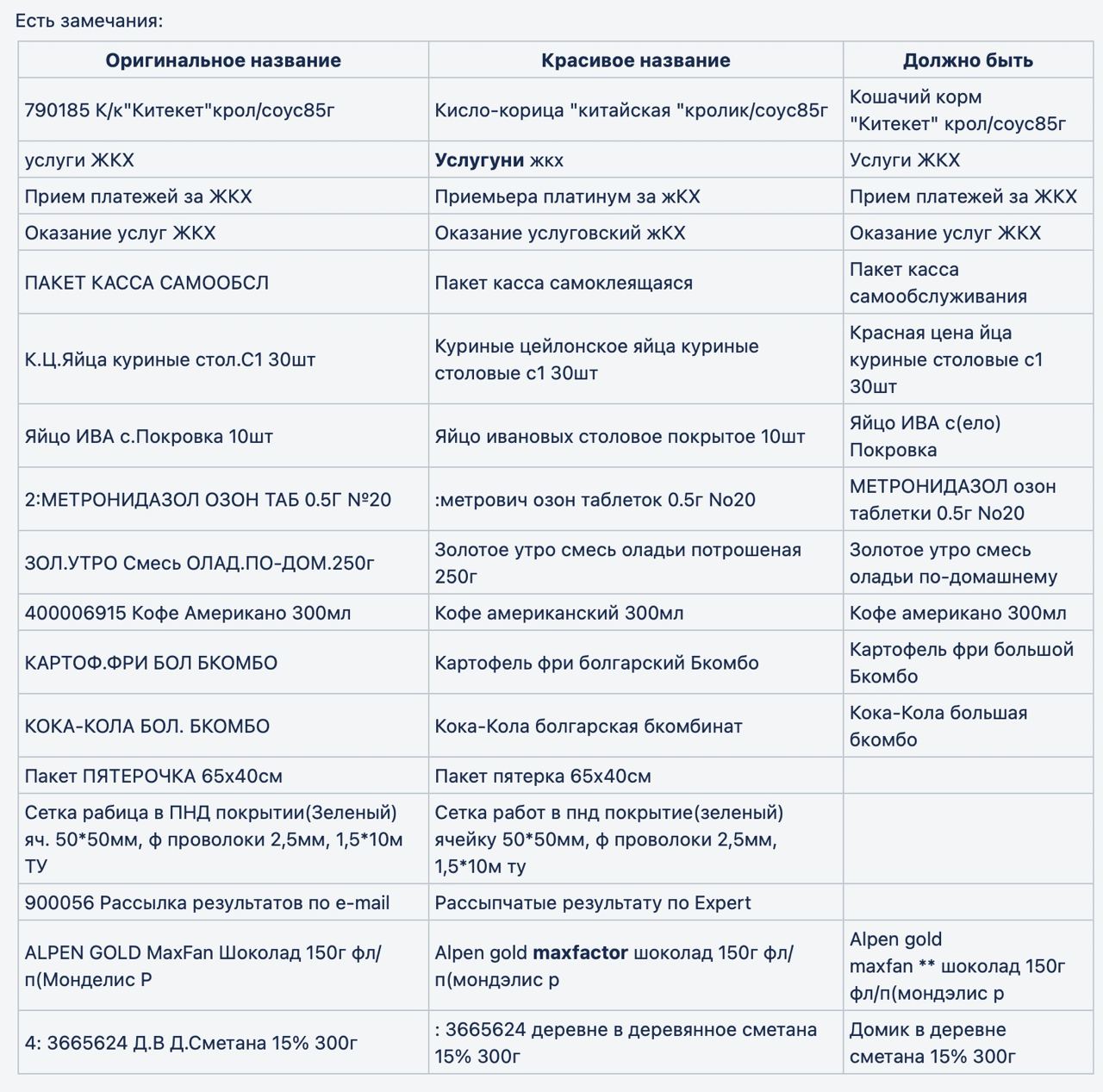
p
Коллеги, добрый день. Подскажите, чем можно воспользоваться, чтобы вытащить с текстов сущности: должность, ФИО?
Что-то вроде Томиты-парсера, Пиморфа или тп.
Например, вот статья на Аифе:
https://aif.ru/health/life/1382963
Отсюда нужно получить:
1-1. директор МОНИКИ, д. м. н.
1-2. Филипп Палеев
2-1. руководитель Московского областного гепатологического центра, главный гепатолог МЗ Московской области
2-2. Павел Богомолов
Еще здесь есть:
3-1. первый заместитель министра здравоохранения МО
3-2. Дмитрий Марков
Вообще пример не простой, здесь много других уникальных названий, но сейчас задача в том, чтобы выделить уникальных персон.
Что-то вроде Томиты-парсера, Пиморфа или тп.
Например, вот статья на Аифе:
https://aif.ru/health/life/1382963
Отсюда нужно получить:
1-1. директор МОНИКИ, д. м. н.
1-2. Филипп Палеев
2-1. руководитель Московского областного гепатологического центра, главный гепатолог МЗ Московской области
2-2. Павел Богомолов
Еще здесь есть:
3-1. первый заместитель министра здравоохранения МО
3-2. Дмитрий Марков
Вообще пример не простой, здесь много других уникальных названий, но сейчас задача в том, чтобы выделить уникальных персон.