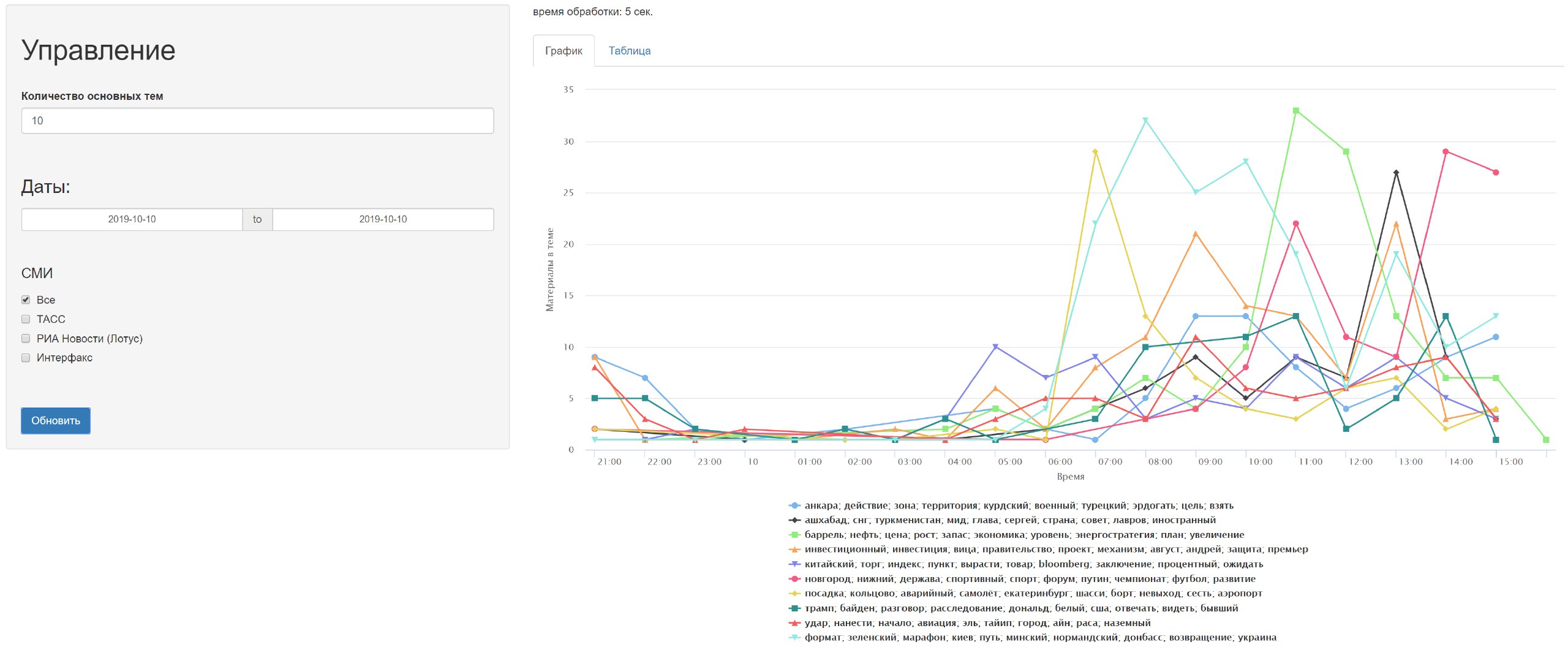
FF
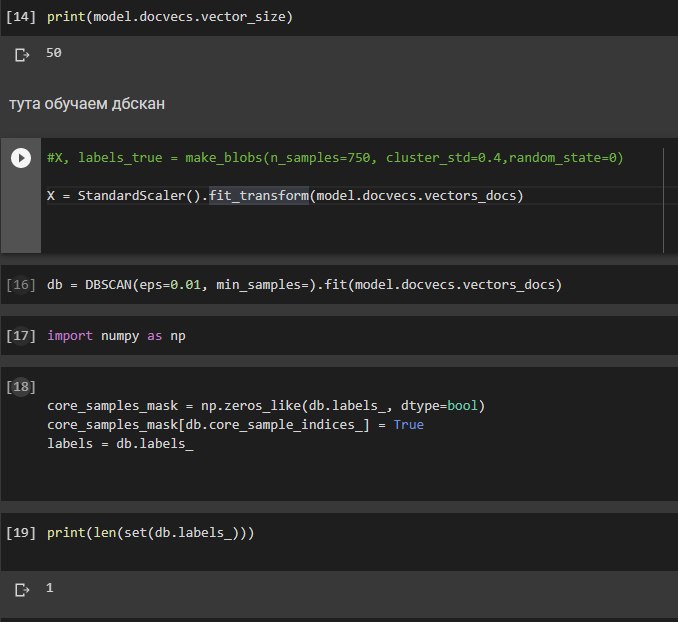
Можно алгоритм агломеративной кластеризации попробовать c разными правилами объединения
Size: a a a
FF
AW
KL
AW
AW
DD
AW
AW
AK
AK
YB
AW
JG
Form('маяковский', Grams(NOUN,Sgtm,Surn,anim,gent,masc,sing)), а для Кутузовского - Form('кутузовский', Grams(ADJF,gent,masc,sing)) Где хранится атрибут Sgtm нашёл: grams.number. А вот где лежит так нужный мне Surn - ну никак. Можно взять из фрозен сета grams.values - но ведь должен же он где-то явно лежать.AB
AW
AB
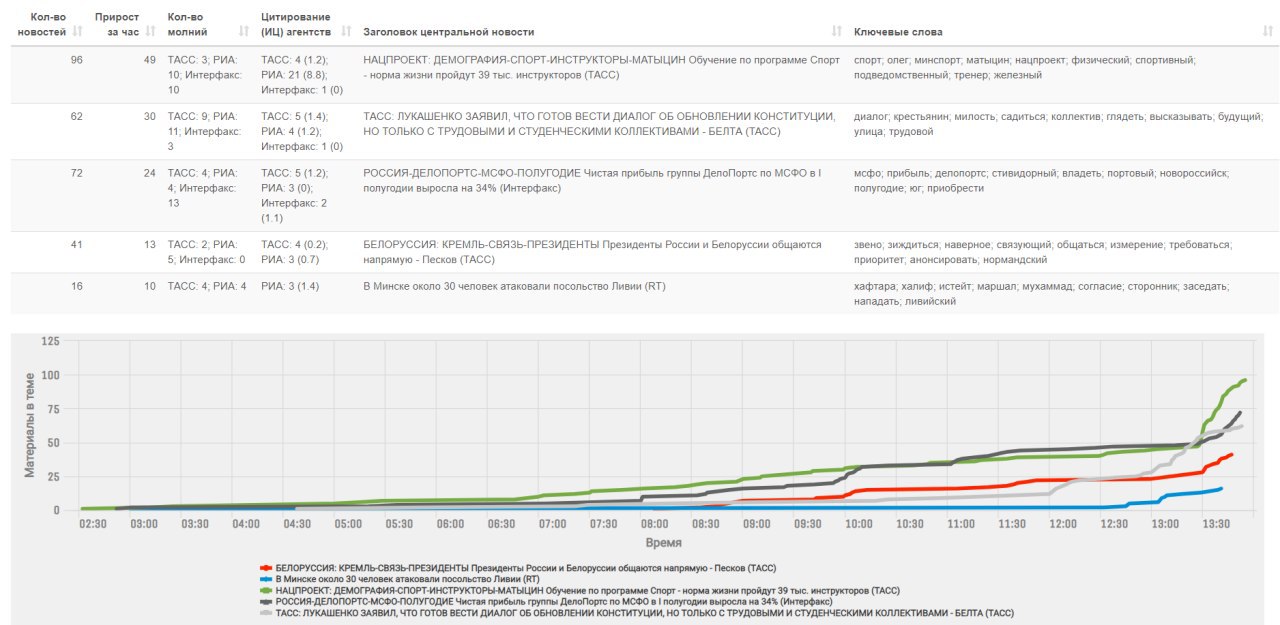
YA
SS
AW
AW