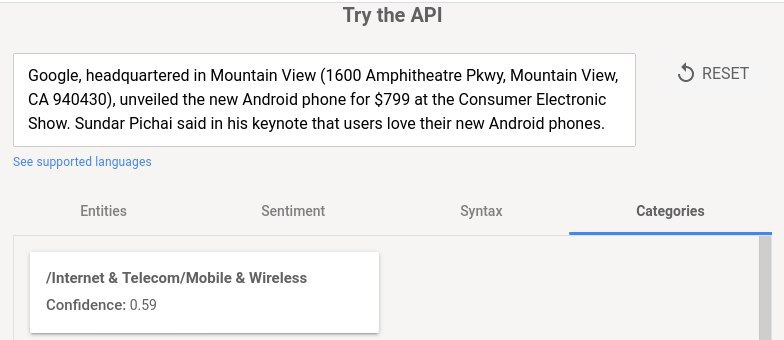
Я начал писать бота для изучения языков. Сейчас у меня уже работает добавление произвольных слов из словаря. Хочется сделать так, чтобы пользователь мог задать класс (к примеру, Computing), и ему сыпались предложения про компьютеры, программирование и всё такое. Предложения планирую брать из корпуса, предварительно снабдив их классами.
Если есть более элегантное решение хотелось бы его услышать.
// Если что, то я делаю бесплатного бота с открытыми исходниками.
Если у тебя заранее списка классов нет, то можно применить к твоему корпусу какой-нибудь алгоритм кластеризации (их много, возьми хоть sklearn, и они работают почти из коробки, надо пару параметров потюнить, типа числа кластеров), и сделать кластеры - классами.