YB
Андрей Ключаревский
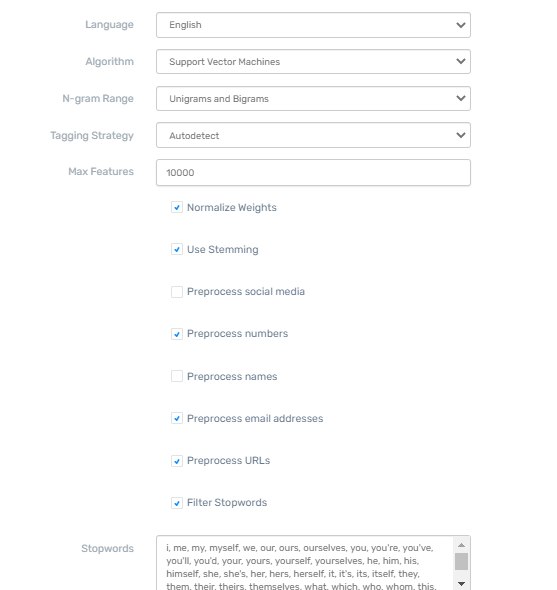
Здравствуйте! Кто может помочь с классификатором ключевых слов на теги "годно", "негодно", "годно+негодно". Данные разметил как в скрине, но лучше, чтобы перевод не склеивался с оргиналом. Хотел через monkeylearn прогрузить, а там лимит 300 запросов.
Буду запускать с вин10. А еще лучше подскажите что-то с двухкнопочным интерфейсом, а то пробовал knime - не зашло
Буду запускать с вин10. А еще лучше подскажите что-то с двухкнопочным интерфейсом, а то пробовал knime - не зашло
уж написать что-то с двухкнопочным интерфейсом для веба можно самому за час.