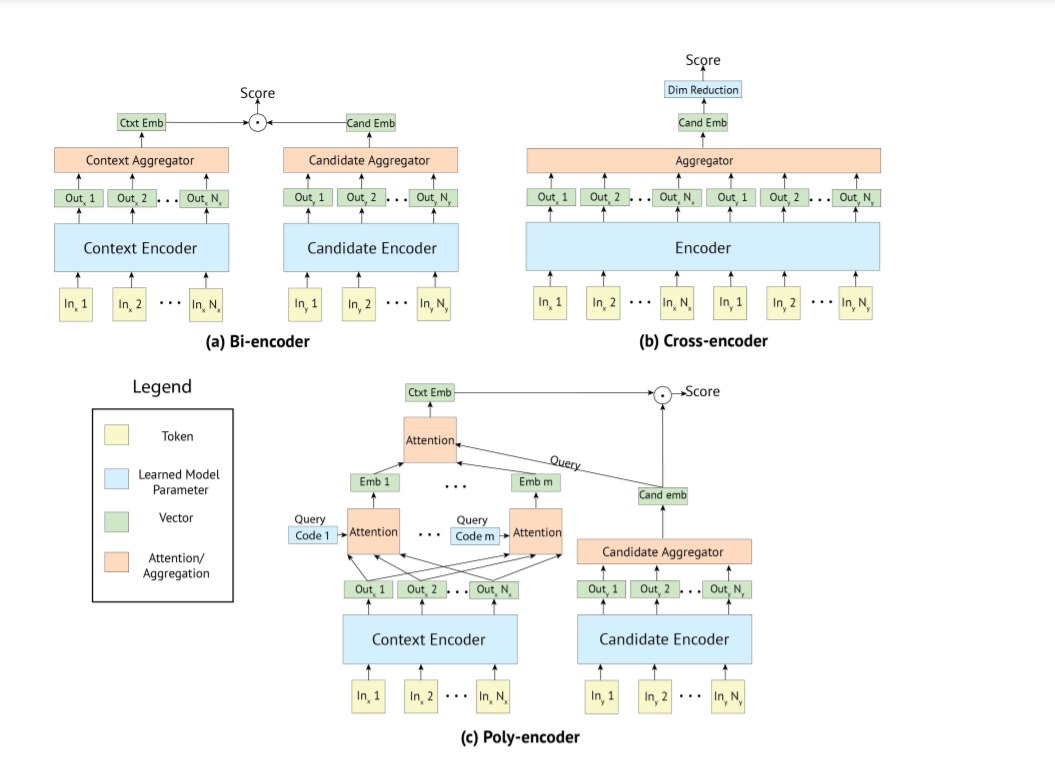
Приветствую, коллеги! Нужна ваша помощь - у меня есть набор данных данных, представляющих собой обращения в корпоративную "горячую линию". Особенность в том, что обращения могут быть анонимными и гласными, то есть в некоторых сообщениях могут быть указаны контактные данные (ФИО, телефон, название организации), а в некоторых просто ФИО "посторонних" людей. Собственно мне и нужно извлечь контакты заявителя, если они в сообщении есть. Я сделал модель, которая достаточно хорошо извлекает именованные сущности (персоны, организации). Но проблема в том, как именно определить, какая из 5-6 персон, упоминаемых в сообщении, является заявителем. Например, сообщение может быть такое "Добрый день! Я Иванов Иван Иванович, работаю в ООО Ромашка. Хочу сообщить, что мой начальник Петров Петр Петрович вместе с бухгалтером ООО Василек задумали темные делишки." Попробовал уже несколько вариантов, например отдельную разметку B-APPLICANT и I-APPLICANT для фразы "Я Иванов Иван Иванович, работаю в ООО Ромашка" - результат не очень, сетка обучиться так и не смогла. Использую DeepPavlov. Подскажите, пожалуйста, идеи - уверен, что подобные задачи успешно решались. Можно просто подсказать направление куда копать:-) Крайне признателен.