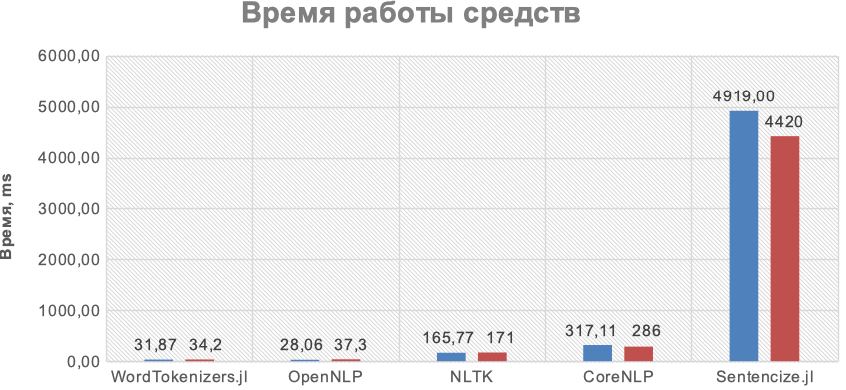
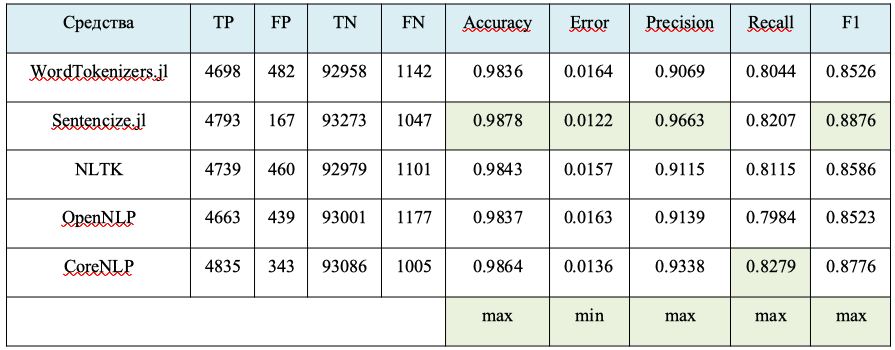
Так 🙂
Сорри за путаницу.
Есть библиотека DeepPavlov, она написана на Python (преимущественно). Её лицензия - Apache 2.0.
Есть Stanford NLP, у которых код на Java (преимущественно). У них есть GPL для некоммерческих проектов и т.д., а для коммерческих - отдельная платная лицензия
Ну, так, если надо проект на Java, то либо OpenNLP, либо Gate, либо CoreNLP с платной лицензией….