Товарищи, возможно кто-то откликнется из вас на мою просьбу.
Давно в голове крутится идея как сделать "конфетку" на тему резервного копирования, но времени в связи плотным графиком работы и учебы чертовски не хватает. Вдруг кто-то захочет сделать её в качестве дипломного проекта - мне не жалко, буду даже рад.
Идея состоит в том, чтобы связать два проекта и получить плюсы от обоих решений.
Первый проект - IPFS - его основная роль заключается в том, чтобы по хешу получить файл, т.е. реализовать связь хеш <-> файл.
Второй проект - fsarchiver - умеет делать резервные копии различных файловых систем, в том числе ntfs(к сожалению, именно она в статусе experimental, не рекомендуется к продакшену).
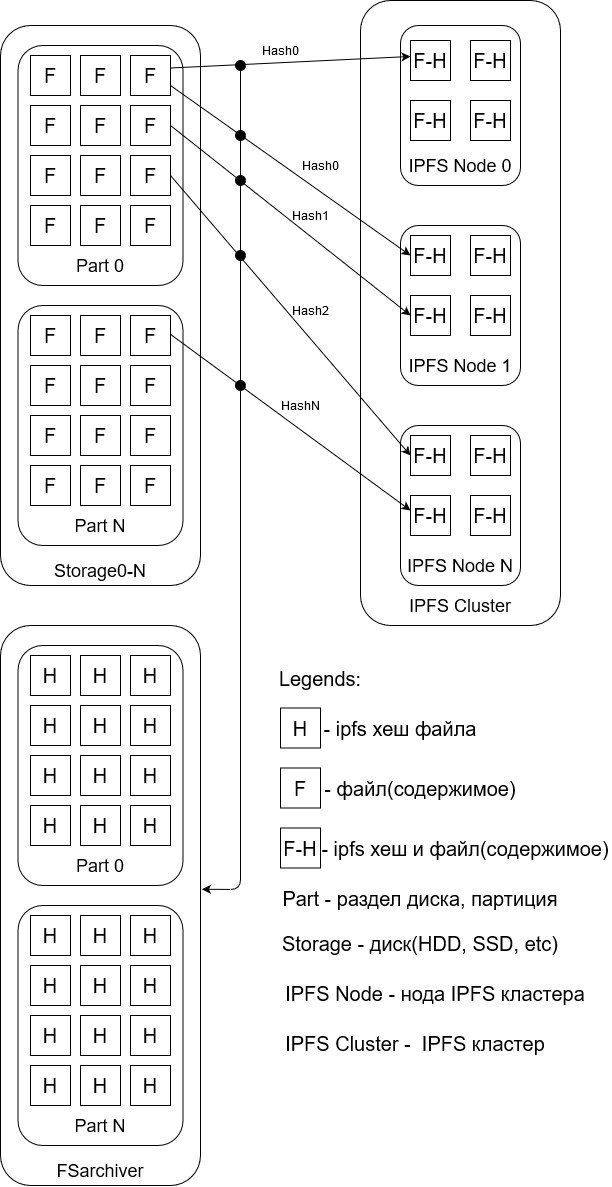
Возможное применение(смотри приложенный рисунок):
1) разворачиваются системы ipfs кластеров, которые хранят на дисках данные и предоставляют интерфейс для загрузки/скачивания файлов.
2) на "бекапируемых" машинах запускается fsarchiver, которые делает резервную копию разделов.
В процессе резервного копирования он обменивается информацией с ipfs кластером на предмет наличия/отсутствия файла и в случае второго вариант он загружает его на кластер.
По итогу работы программа выдает "рецепт" сборки раздела.
3) когда требуется восстановить/расклонировать разделы, то fsarchiver скармливается архив, полученный на предыдущем пункте и он уже, общаясь с ipfs кластером, собирает разделы обратно.
Из плюсов данного решения:
1) меньше тратим места на файлы, не храним один и тот же файл несколько раз в одном месте.
Если требуется наоборот сделать упор на отказоустойчивость, то настройки кластера(я думаю) позволяют этот момент реализовать или банально в лоб скопировать файлы и разнести на другие хранилки.
2) если файловое хранилище у ipfs кластера падает, но есть возможность восстановить файлы, то загнать их в ipfs кластер не составит большого труда.
3) дифференциальные/инкрементальные архивы можно будет также реализовать на этом дополнении со всеми плюсами.
4) пересылать рецепты среди филиалов, а не целые бекапы синхронизировать.
Что может подтянуться локально с вашего ipfs кластера, подтягивается с кластера.
Что может подтянуться с интернета, подтягивается с интернета.
Что может подтянуться из вашего офиса, подтягивается из офиса.
Жирный плюс здесь заключается в том, что, как и в технологии торрентов(@Сахаров, здравия желаю), каждый пир делает маленькую работу, но по факту выполняется большое дело.
5) другие, которые сразу в голову и не придут, но они точно есть. :)
Из минусов:
1) это надо проверить -> для проверки это надо реализовать -> ради этого и публикую сей пост.
2) завлечены два относительно не больно популярных проекта среди админов, будет много отладки и прочих неприятных вещей, хотя на бумаге всё чисто-крыто.
3) более долгая сборка рецепта, т.к. хеширование здесь на каждом углу
4) другие
По поводу реализации куда смотреть, чего читать:
1)
https://github.com/fdupoux/fsarchiverЧто требуется сделать сразу:
- в заголовок добавлять ipfs-hash, указав ключ
- добавить ключ, который позволяет не хранить содержимое файлов в архиве
- общение с ipfs(для относительной простоты даже не кластером, а просто ipfs пиром), а именно скачивание/проверка существования/загрузка файла по его хешу.
На мой взгляд, это минимальный набор, который позволит посмотреть работает эта задумка или нет.
2)
https://habr.com/ru/users/ivan386/posts/ - очень классно написано по поводу ipfs.
3) Google -> IPFS.