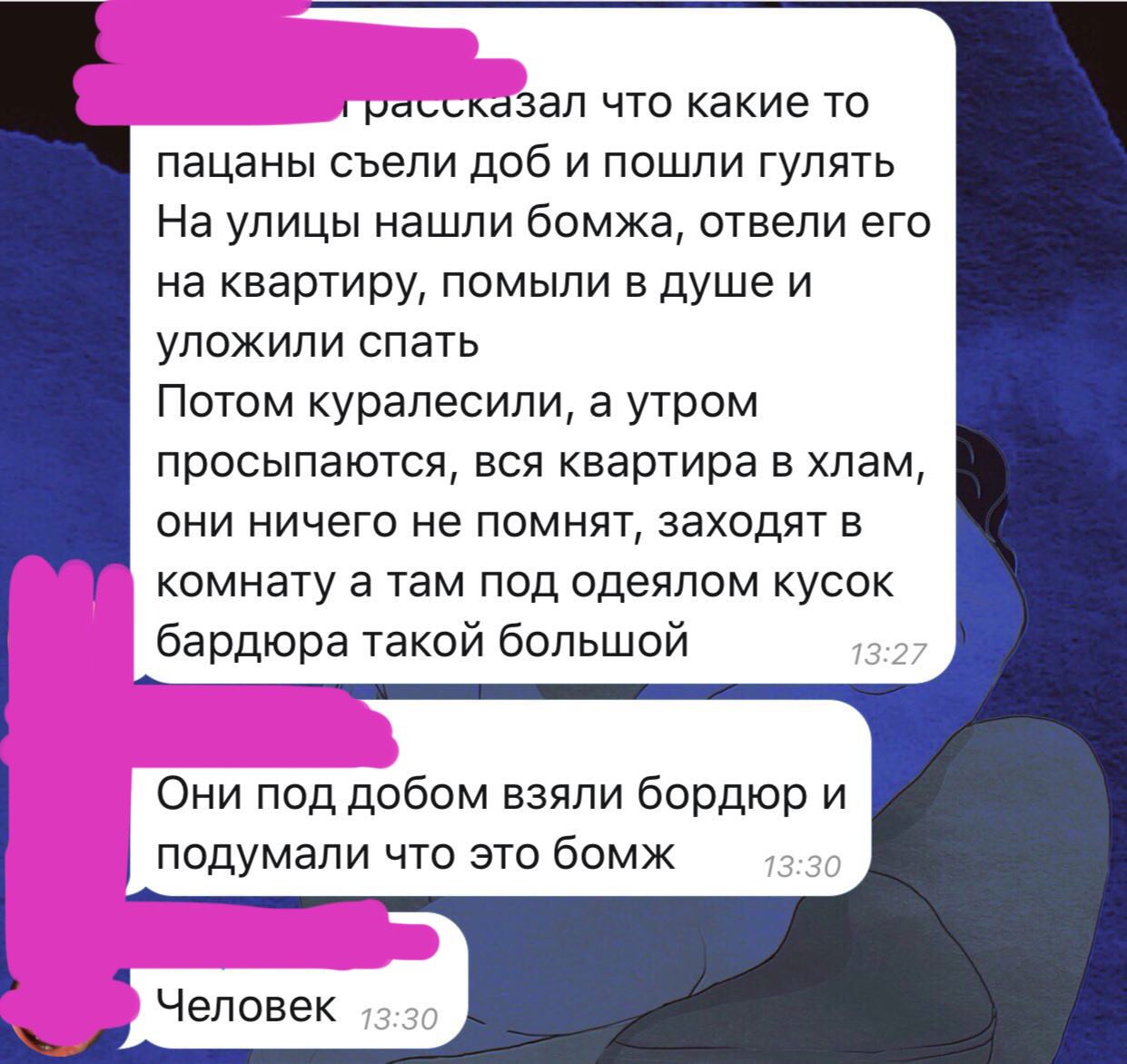
Так только с монгольским получается? Значит старую проблему не пофиксили.
Мой опыт общения с гуглтраном и авторректом подсказывают, что это может быть случаем языка мало корректированного по выдаче, при этом с переводом построенным на каком то языковом эталоне - в данном случае это вполне может быть какая-нибудь тибетская книга мёртвых или что-то другое с устоявшимся переводом. В итоге по длине фраз/строк подбирается конструкция, по какому-то алгоритму наиболее похожая или скорее всего перестроенная другим алгоритмом на логику языка пользователя