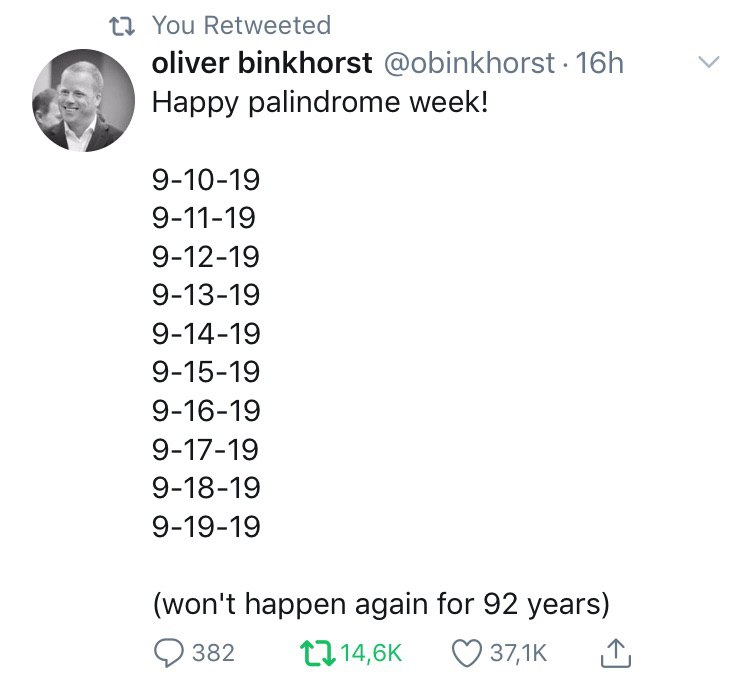
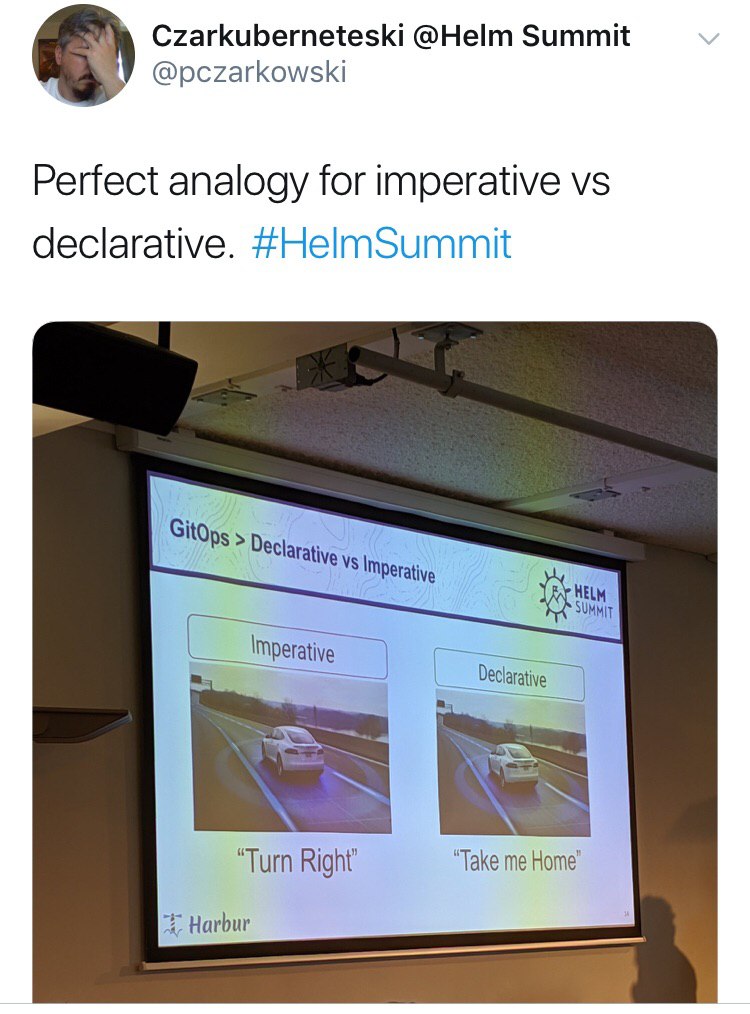
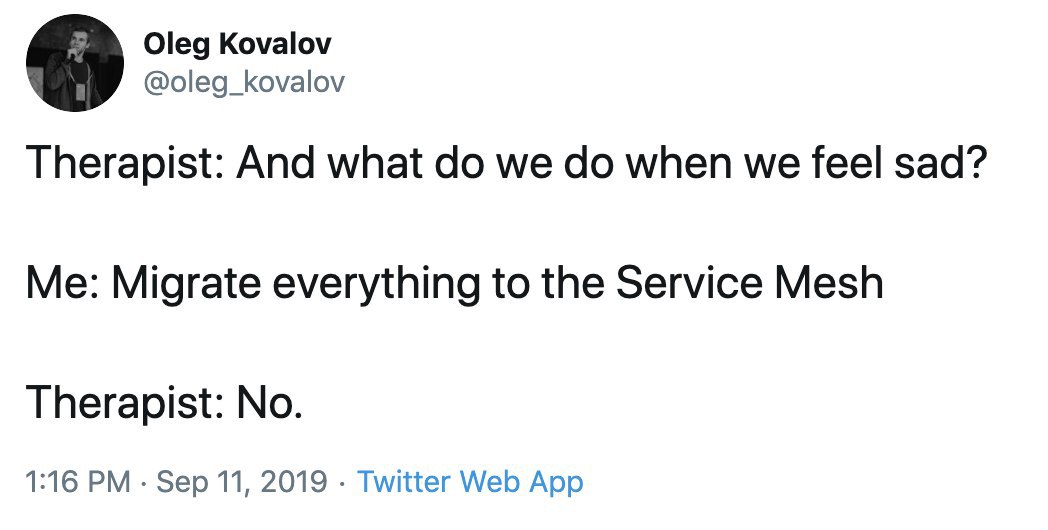
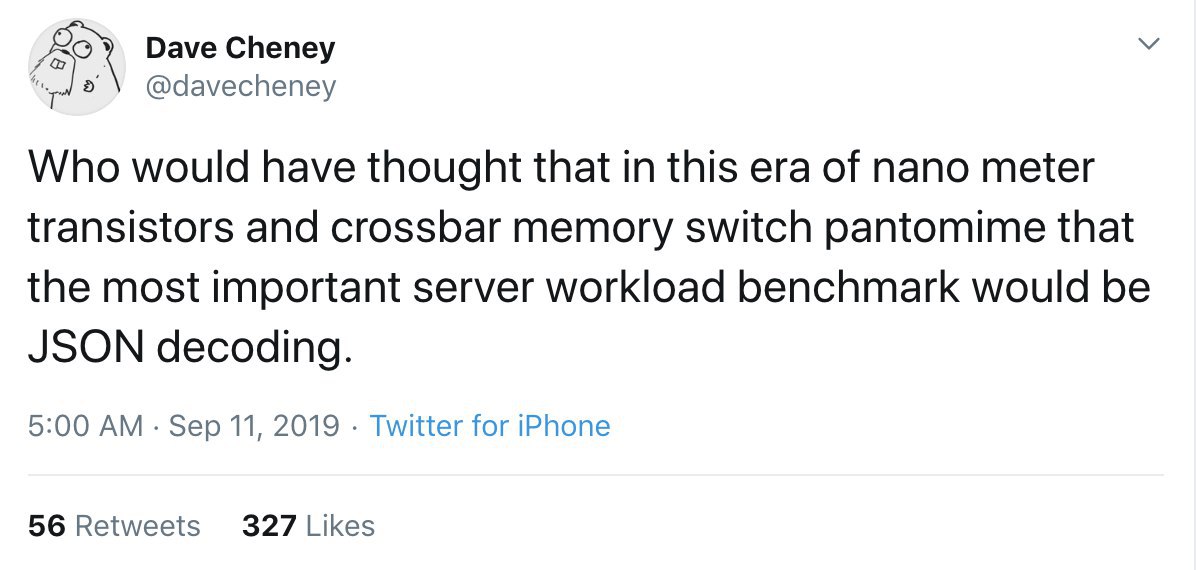
Вчера при помощи друга-товарища Чебуряша настроил форвард почты с *@olegk.dev на мыло гугла.
И все это великолепие живет без GSuite и Google Domains (цены у каждого смешные, но бесячие, вещь простая ж). Вариант держать свой почто-сервер не вариант.
Спас меня http://improvmx.com/ кроме того что все заняло минуту, он ещё и бесплатный, но я так был рад, что купил подписку, почему бы и не.
Осталось понять что теперь делать со всей это мощью 🤔
И все это великолепие живет без GSuite и Google Domains (цены у каждого смешные, но бесячие, вещь простая ж). Вариант держать свой почто-сервер не вариант.
Спас меня http://improvmx.com/ кроме того что все заняло минуту, он ещё и бесплатный, но я так был рад, что купил подписку, почему бы и не.
Осталось понять что теперь делать со всей это мощью 🤔