



u
Size: a a a
2021 April 07
DB
А где офис будет? 🌚
E

зато иконка теперь есть у каждого проекта ☝️😀

V
Ладожская
S
Фаберже?
S
В Берлин больше не возите?)
V
БЦ Лада
Энергетиков 3А
Энергетиков 3А
V
Возим. Мне кажется сейчас это может быть затруднено из-за короноправил разных государств
V
Ну и не все хотят переезжать. Надо уважать интересы людей 😄
AZ
ждем сторис
2021 April 08
Б
Кто-нибудь знает утилиту, которая переписывает
unittest.TestCase.assert на обычные assert?MK
sed
S
АП
PyCharm ещё
Б
TD
Привет
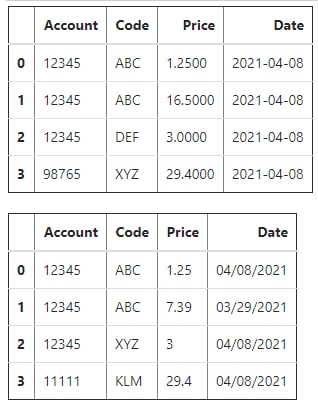
У меня возникла проблема с пандасом, возможно, кто-нибудь сможет подсказать.
Есть два датафрейма с одинаковыми столбцами, но разным форматом данных.
Мне нужно взять все строки из обоих датафреймов с совпадающими значениями в двух конкретных столбцах и убедиться, что данные в остальных столбцах тоже совпадают (с учётом разницы в форматах).
При этом эти пары столбцов не уникальны по значениям; одна и та же пара может быть в нескольких строках.
Как бы мне лучше эти датафреймы сравнить при таких условиях?
Тупой проход циклом выглядит ужасно неэффективным, т.к. в датафреймах сотни тысяч строк.
Я нашёл метод
Может, есть что-то ещё, что мне может помочь в этой задаче?
Приложил скрин для примера - в нём, по идее, "совпадают" только первые строки.
У меня возникла проблема с пандасом, возможно, кто-нибудь сможет подсказать.
Есть два датафрейма с одинаковыми столбцами, но разным форматом данных.
Мне нужно взять все строки из обоих датафреймов с совпадающими значениями в двух конкретных столбцах и убедиться, что данные в остальных столбцах тоже совпадают (с учётом разницы в форматах).
При этом эти пары столбцов не уникальны по значениям; одна и та же пара может быть в нескольких строках.
Как бы мне лучше эти датафреймы сравнить при таких условиях?
Тупой проход циклом выглядит ужасно неэффективным, т.к. в датафреймах сотни тысяч строк.
Я нашёл метод
compare, но он, как я понимаю, просто сравнивает строки с совпадающими индексами. Даже если я как-то предварительно нормализую оба датафрейма, не понятно, как решить проблему с неуникальными парами, по которым нужно искать строки для сравнения.Может, есть что-то ещё, что мне может помочь в этой задаче?
Приложил скрин для примера - в нём, по идее, "совпадают" только первые строки.
AZ
А ты можешь их отсортировать как-нибудь так, чтобы потом одного прохода с попарным сравнением записей было бы достаточно?
TD
Что-то типа
К сожалению, нет - нет гарантий, что они будут совпадать. Например, в одном датафрейме может быть три строки с одной парой значений, а в другом - только две.
for row1, row2 in zip(df1, df2), я правильно понял?К сожалению, нет - нет гарантий, что они будут совпадать. Например, в одном датафрейме может быть три строки с одной парой значений, а в другом - только две.