ダ
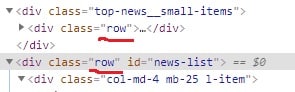
Вот исходник:
как извлечь оттуда хреф, то есть линк?
Этот метод не работает. В чем ошибка?
<a class="news__title" href="линк">текст</a>как извлечь оттуда хреф, то есть линк?
url = answer.find('a',class_='news__title').a.get('href')Этот метод не работает. В чем ошибка?
кажется ты вообще неправильно делаешь