Однажды, я уже рассказывал вам, как использовать встроенную сортировку в Python. Убежден, что для разработчиков уровня middle и выше важно также знать, как она работает внутри. Ответ нашелся на канале Python in depth. Очень познавательно и наглядно.
Size: a a a
class Foo:
def __init__(self, x):
self.x = x
def __hash__(self):
return self.x
def __eq__(self, other):
return self.x == other.x
def __repr__(self):
return f'Foo({self.x})'
# создаем set из трех разных объектов
hacker = Foo(20)
s = {Foo(10), hacker, Foo(30)}
print(s) # {Foo(10), Foo(20), Foo(30)}
hacker.x = 30 # взлом системы
print(s) # {Foo(10), Foo(30), Foo(30)}
from collections import Counter
c = Counter(s)
print(c) # Counter({Foo(30): 2, Foo(10): 1})s2 = set(list(s))
print(s2) # {Foo(10), Foo(30)}s.copy() не сработает, потому что он копирует уже вычисленные хэши.
>>> 0.1 + 0.1 + 0.1 == 0.3
False
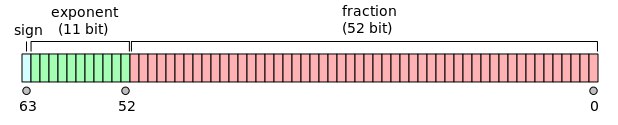
Число = ±мантисса * (2 ** экспонента)2**64 разных чисел (64 позиции по 2 варианта), а на деле их и того меньше. Диапазон чисел, представимых таким форматом составляет: ±1.710E-308 до 1.710E+308. То есть от очень малых по модулю чисел, до очень больших. Допустимые числа на числовой прямой распределены неравномерно: гуще в районе нуля и реже в районе огромных чисел.0.1 = 1 / 10 ≈ J / (2**N) или J ≈ 2**N / 10>>> 2**52 <= 2**56 // 10 < 2**53
True
>>> divmod(2**56, 10)
(7205759403792793, 6)
7205759403792793 + 1 = 7205759403792794. Таким образом, это будет ближайшее к 0.1 число, возможное в представлении float. Доказательство проверкой:>>> 7205759403792794 / 2 ** 56 == 0.1
True
>>> format(0.1 + 0.1 + 0.1 - 0.3, '.56f')
'0.00000000000000005551115123125782702118158340454101562500'git commit:GIT_AUTHOR_DATE='новая-дата' GIT_COMMITTER_DATE="$GIT_AUTHOR_DATE" git commit -m 'сообщение'date. Выяснилось, что date имеет совершенно разный синтаксис на Linux и macOS, поэтому я решил все это дело упростить скриптом на Python.date = datetime.now() - timedelta(days=days)
os.environ['GIT_AUTHOR_DATE'] = os.environ['GIT_COMMITTER_DATE'] = date.isoformat()
r = os.system(f'git commit -m "{message}"')
exit(r)commit-ago (без расширения) и добавим в начале шебанг, иными словами заголовок, указывающий интерпретатор для скрипта.#!/usr/local/bin/python3which python3chmod +x commit-agoPATH, чтобы можно было запускать скрипт без указания полного адреса. Неплохое место: mv commit-ago /usr/local/bincommit-ago. touch foo.txt
git add foo.txt
commit-ago 1 "I did it yesterday"

float и его подводные камни. В области финансов и бизнеса бывает недопустимо совершать ошибки в расчетах. Компьютер должен помогать человеку считать, и он должен делать это точно и по правилам, которые привычны и интуитивны для нас. Короче говоря, как учат в школе. А учат нас десятичным дробям, то есть тем, представление которых записывается через степени числа 10. А float построен вокруг степеней числа 2, что удобнее и проще для двоичных компьютеров, но контр-интуитивно для человека:>>> 0.1 + 0.1 + 0.1 == 0.3
False
>>> from decimal import Decimal as d
>>> d('0.1') + d('0.1') + d('0.1') == d('0.3')
Truefib = {}
a, b = 1, 1
for fib[a] in range(1, 100):
a, b = a + b, a
print(fib[13]) # это №6 число Фиб.
print(fib[433494437]) # это №42 число Фиб.
print(fib[10]) # KeyError - 10 - это не число Фиб.fib[a] будет присвоено число из range(1, 100). Но на каждой итерации будет свое a – новое число Фибоначчи:fib[1] = 1
fib[2] = 1 + 1 = 2
fib[3] = 2 + 1 = 3del x вызывает метод x.__del__. Это неправда. Python использует механизм подсчета ссылок, и del x – лишь один из способов уменьшить количество ссылок на 1.class Bazooka:Важные нюансы:
def __del__(self):
print('Bazooka.__del__()')
>>> b = Bazooka() # тут мы привяжем новый объект Bazooka() к имени переменной b (1 ссылка)
>>> del b # тут мы удаляем имя b, объект отвязывется, ссылок - 0, вызывается деструктор.
Bazooka.__del__()
>>> b = Bazooka()
>>> b = None # имя b не удалено, но объект будет отвязан от него и деструктор вызовется
Bazooka.__del__()
>>> b = Bazooka()
>>> b2 = b # объект привязан и к b, и к b2 (ссылок - 2)
>>> del b # удаляем первый, ссылок - 1, деструктор не вызван
>>> del b2 # удаляем второй, ссылок - 0, деструктор вызывается
Bazooka.__del__()
sys.last_traceback = None)zip:>>> x = [1, 2, 3, 4, 5]
>>> y = ['one', 'two', 'three']
>>> list(zip(x, y))
[(1, 'one'), (2, 'two'), (3, 'three')]zip останавливается, как только в одном списков закончились значения. А в списке x остались бесхозные числа 4 и 5.zip_longest из стандартного модуля itertools. Если в одном из списков кончились значения, то zip_longest будет ставить на их место None, и закончит работу только тогда, когда каждый из списков будет исчерпан.>>> import itertools
>>> list(itertools.zip_longest(x, y))
[(1, 'one'), (2, 'two'), (3, 'three'), (4, None), (5, None)]
zip и zip_longest могут принимать не только два аргумента, а произвольное число входных аргументов, т.е. можно делать из трех списков тройки, из четырех – четверки и так далее.list, чтобы извлечь все значения итератора в список. Конечно, можно извлекать пары по одной в ленивом режиме функцией next:>>> it = itertools.zip_longest(x, y)
>>> next(it)
(1, 'one')final. B для класса A, вызывается метод new метакласса A. В этом методе мы проверим, есть ли среди базовых классов (bases) хоть один, чьим метаклассом является Final, если да – бросим исключение, сигнализирующее, что нельзя создать подкласс. Если среди базовых классов нет таких, то вызовем стандартный super().__new__. Вот так выглядит код метакласса:# метакласс наследуется от Type
class Final(type):
def __new__(mcls, name, bases, attrs):
for base in bases:
# является ли тип класса подклассом Final
if issubclass(type(base), Final):
# тогда - ошибка! нельзя содзать подкласс Final
raise TypeError(f'{name} is final!')
# иначе - обычное поведение
return super().__new__(mcls, name, bases, attrs)
Как пользоваться:
# тут отработает Final.__new__ для A - успешно
class FinalA(metaclass=Final):
...
# тут отработает Final.__new__ для B - с ошибкой!
class B(FinalA):
...@final
class A:
...
final! Но, он относится только к подсказкам типов (type hinting), и объявление подкласса от final класса не даст никаких ошибок!from typing import final
@final
class A:
...
# никаких ошибок
class B(A):
...➜ 2 mypy final38.py
final38.py:8: error: Cannot inherit from final class "A"
Found 1 error in 1 file (checked 1 source file)comprime(*numbers), которая принимает произвольное количество аргументов – натуральных чисел, и проверяет, являются ли все эти числа взаимно простыми, то есть не имеют общих делителей, кроме 1.>>> coprime(13, 20)
True
>>> coprime(13, 26)
False
>>> coprime(2, 3, 5, 7, 11)
True
# стратегия печатать на экран
def console_writer(info):
print(info)
# стратегия выводить в файл
def file_writer(info):
with open('log.txt', 'a') as file:
file.write(info + '\n')
def client(writer):
writer('Hello world!')
writer('Good bye!')
# пользователь выбирает стратегию
if input('Write to file? [Y/N]') == 'Y':
client(writer=file_writer)
else:
client(writer=console_writer)client даже не знает, какой вариант алгоритма ей дадут. Она знает лишь то, что writer(info) – это некая функция, принимающая строку (это и есть общий интерфейс для всех стратегий). Таким образом, мы делегируем работу стратегиям, скрывая детали реализации каждой из них.class Adder:
def do_work(self, x, y):
return x + y
class Multiplicator:
def do_work(self, x, y):
return x * y
class Calculator:
def set_strategy(self, strategy):
self.strategy = strategy
def calculate(self, x, y):
print('Result is', self.strategy.do_work(x, y))
calc = Calculator()
calc.set_strategy(Adder())
calc.calculate(10, 20)
calc.set_strategy(Multiplicator())
calc.calculate(10, 20)Calculator. Для простоты, здесь я не применял наследование (спасибо динамической природе Python), но в серьезных проектах, вам следовало бы написать что-то подобное:from abc import ABC, abstractmethod
class BaseStrategy(ABC):
@abstractmethod
def do_work(self, x, y):
pass
class Adder(BaseStrategy):
def do_work(self, x, y):
return x + y
class Multiplicator(BaseStrategy):
def do_work(self, x, y):
return x * y
class Calculator:
def set_strategy(self, strategy: BaseStrategy):
self.strategy = strategy
def calculate(self, x, y):
print('Result is', self.strategy.do_work(x, y))BaseStrategy – как абстрактный класс ABC. Далее в каждой стратегии реализуем этот интерфейс.
pip install bitfrom bit import Key
my_key = Key('L3Bc5K68nfDzaW4n4ag7eERKGw6WvsvTmqvirzn1wut7uL3sg76o')my_key.send([
('1HB5XMLmzFVj2ALj6mfBsbаfRoD4miY36v', 0.0024, 'btc'),
], message='За кофе')drinks = [
('Juice', 100),
('Beer', 200),
('Soda', 50),
('Cocktail', 400),
('Water', 20)
]
sorted передать параметр key – функцию, которая достанет из кортежа элемент с индексом 1 – цену. Можно поступить разными способами. Способ 1 – lambda:>>> sorted(drinks, key=lambda d: d[1])
[('Water', 20), ('Soda', 50), ('Juice', 100), ('Beer', 200), ('Cocktail', 400)]operator.itemgetter:>>> from operator import itemgetter
>>> sorted(drinks, key=itemgetter(1))
[('Water', 20), ('Soda', 50), ('Juice', 100), ('Beer', 200), ('Cocktail', 400)]key, то приглашаю прочитать новую заметку. Еще там есть про сортировку по нескольким признакам и про сравнение производительности разных способов задания key.try-except.IndexError, если индекс отсутствует в списке, и KeyError, если ключ отсутствует в словаре. Однако, лучше ловить LookupError, который является предком обоих исключений:>>> issubclass(KeyError, LookupError)
True
>>> issubclass(IndexError, LookupError)
Trueconfig = {}
try:
admin = config['db'][0]['admins']['list'][0]
except LookupError:
admin = 'all'dict.setdefault(key, default). Этот метод проверяет, есть ли ключ в словаре, если его нет, то в словарь добавляется значение по умолчанию, и оно же возвращается. А если ключ был в словаре, то вернется значение по этому ключу. Поэтому такой неуклюжий код:if 'workers' not in config:
config['workers'] = 8
workers = config['workers']workers = config.setdefault('workers', 8) default не поменяет уже записанное в первый раз значение:>>> d = {}
>>> d.setdefault('foo', 10)
10
>>> d.setdefault('foo', 20)
10PATTERN = 'PyWay'
def predicate(addr: str):
# первый символ – ID сети, пропустим его
return addr[1:].startswith(PATTERN)from bit import Key
while True:
k = Key() # новый случайны ключ
if predicate(k.segwit_address):
print(f'{k.segwit_address} with WIF private key {k.to_wif()}')
break