



PU
Size: a a a
2020 December 19
a
все верно glmer и логит реграссия со смешанными эффектами
ИП
Здравствуйте, все.
У меня вопрос про LMER/GLMER
Я меряю то, как хорошо испытуемые видят штуку (ответ 0 - неправильно; 1 -правильно)
И смотрю как время (это не континуум, у него 4 категории) и локация (тоже 4 категории) влияют на эти ответы.
Короче, я делаю Response~time*location+(1|participant), а дальше вопрос: с одной стороны этот самый Response – binomial, и для него есть GLMER с другой стороны, я же как бы долю правильных ответов в каждом отдельном временном отрезке смотрю, тогда вроде как уже не binomial, тогда LMER. Или тут важна нормальность распределения, а не тип зависимой переменной? Тогда как ее проверить?
Хотелось бы понять, как_правильно_это_делать.
У меня вопрос про LMER/GLMER
Я меряю то, как хорошо испытуемые видят штуку (ответ 0 - неправильно; 1 -правильно)
И смотрю как время (это не континуум, у него 4 категории) и локация (тоже 4 категории) влияют на эти ответы.
Короче, я делаю Response~time*location+(1|participant), а дальше вопрос: с одной стороны этот самый Response – binomial, и для него есть GLMER с другой стороны, я же как бы долю правильных ответов в каждом отдельном временном отрезке смотрю, тогда вроде как уже не binomial, тогда LMER. Или тут важна нормальность распределения, а не тип зависимой переменной? Тогда как ее проверить?
Хотелось бы понять, как_правильно_это_делать.
Так все-таки доля (как усредненные значения по условию) или правильно/неправильно?
OS
Иван Поздняков
Так все-таки доля (как усредненные значения по условию) или правильно/неправильно?
изначально 0/1, но они же аггрегируются, или как это назвать (1000 трайлов каждый сделал - вот и по 250 трайлов на отрезок времени появились) 🤷🏻♀️
ГД
Доля - это тоже логистическая регрессия. В хелпе к обычному glm написано что можно задать целевую переменную, как матрицу. В одной колонке количество успехов, в другой количество неуспехов:
For binomial and quasibinomial families the response can also be specified as a factor (when the first level denotes failure and all others success) or as a two-column matrix with the columns giving the numbers of successes and failures.
For binomial and quasibinomial families the response can also be specified as a factor (when the first level denotes failure and all others success) or as a two-column matrix with the columns giving the numbers of successes and failures.
OS
Доля - это тоже логистическая регрессия. В хелпе к обычному glm написано что можно задать целевую переменную, как матрицу. В одной колонке количество успехов, в другой количество неуспехов:
For binomial and quasibinomial families the response can also be specified as a factor (when the first level denotes failure and all others success) or as a two-column matrix with the columns giving the numbers of successes and failures.
For binomial and quasibinomial families the response can also be specified as a factor (when the first level denotes failure and all others success) or as a two-column matrix with the columns giving the numbers of successes and failures.
Спасибо
AC
изначально 0/1, но они же аггрегируются, или как это назвать (1000 трайлов каждый сделал - вот и по 250 трайлов на отрезок времени появились) 🤷🏻♀️
Агрегировать не обязательно, даже не нужно (при подсчете процента теряется информация о числе проб)
OS
Агрегировать не обязательно, даже не нужно (при подсчете процента теряется информация о числе проб)
но мне нужно в данном случае=(
AC
Зачем?
AC
Или считай сумму правильных и неправильных как тут выше писали и задавай их вместе как зависимую переменную
2020 December 20
AS
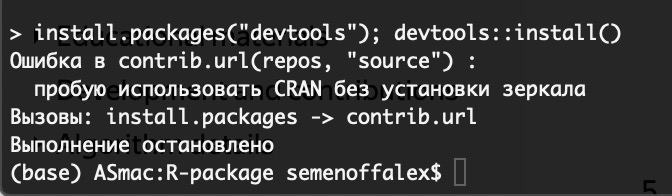
Пытаюсь установить catboost на mac по официальной инструкции (https://catboost.ai/docs/installation/r-installation-local-copy-installation.html) и получаю вот такую ошибку. Что делать?
AS
В общем, установил с гита
ЕТ
Стыдно, но напомните альтернативу тесту Мак-Немара для шкалы > 2 классов, пожалуйста.
ЕТ
Хм. Тест Мак-Немара-Боукера. Вшита в mcnemar.test, судя по всему.
ЕТ
Т.е. у меня люди отвечают на вопрос с пятью вариантами ответа, потом читают текст, а потом опять отвечают на вопрос с пятью вариантами ответа. И так ещё раз.
И я хочу посмотреть, значимо ли различается распределение ответов в трёх точках.
И я хочу посмотреть, значимо ли различается распределение ответов в трёх точках.
AS
Тоже не вышло. Я оба варианта попробовал.
Код ошибки для запроса
Код ошибки для запроса
> dbSendQuery(conn = con, statement = query)Код ошибки для dbWriteTable
Ошибка: nanodbc/nanodbc.cpp:1617: HY000: HTTP status code: 500
Received error:
Code: 497, e.displayText() = DB::Exception: ant: Not enough privileges. To execute this query it's necessary to have the grant CREATE DATABASE ON Test.* (version 20.3.16.165 (official build))
Ошибка в new_result(connection@ptr, statement, immediate) :
nanodbc/nanodbc.cpp:1556: HY000: HTTP status code: 400
Received error:
Code: 62, e.displayText() = DB::Exception: Syntax error: failed at position 61 (end of query) (line 4, col 1): . Expected one of: storage definition, ENGINE (version 20.3.16.165 (official build))
Так что в итоге вышло-то?
БА
Так что в итоге вышло-то?
А в итоге даже не вошло.

AS
Да-да))
Блин, теперь бы ту переписку найти =( По словам clickhouse/кликхаус пока не удалось. Там вроде какие-то ссылки полезные были.
IY
Т.е. у меня люди отвечают на вопрос с пятью вариантами ответа, потом читают текст, а потом опять отвечают на вопрос с пятью вариантами ответа. И так ещё раз.
И я хочу посмотреть, значимо ли различается распределение ответов в трёх точках.
И я хочу посмотреть, значимо ли различается распределение ответов в трёх точках.
Обычный хи-квадрат тут тоже можно использовать