



AS
Была статья Бурнаева (или кого-то, с кем я его постоянно путаю), согласно которой СМОТЕ всех забарывает, только вот параметры под него хз как подбирать (кол-во объектов, которые надо сгенерировать, и т.д.).
Size: a a a
AS
AS
E
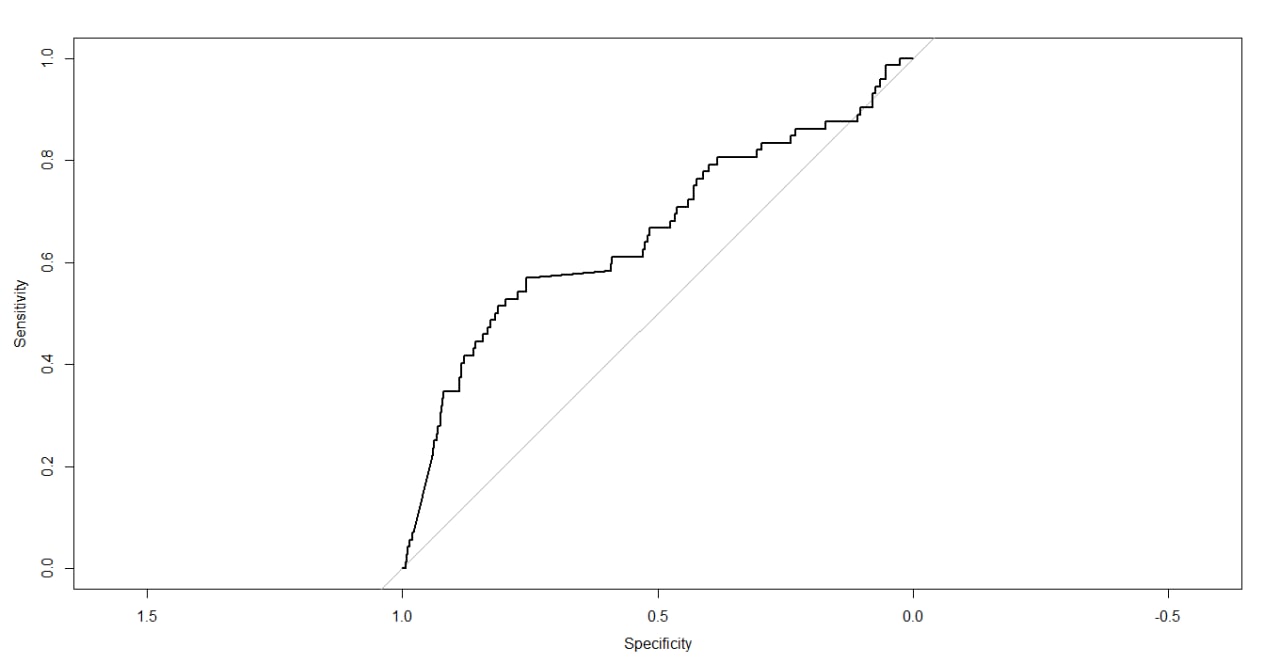
AS
АК
AS
AB
AB
AS
AB
AS
AB
E
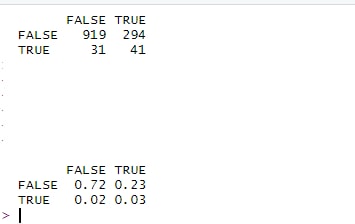
AS
AB
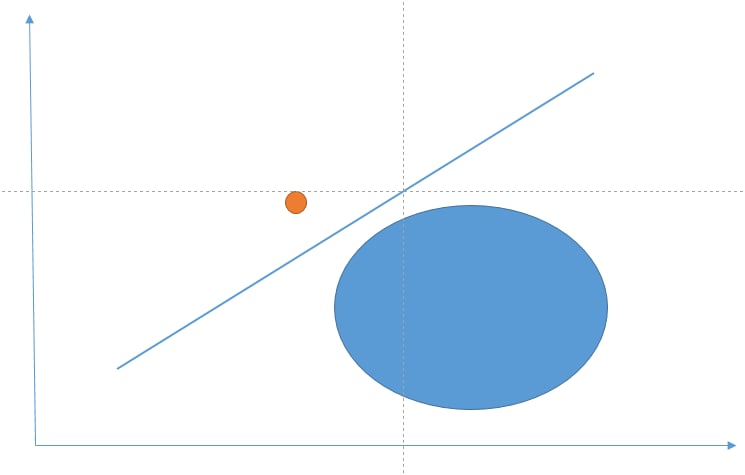
AS
AB
AB
E
AB