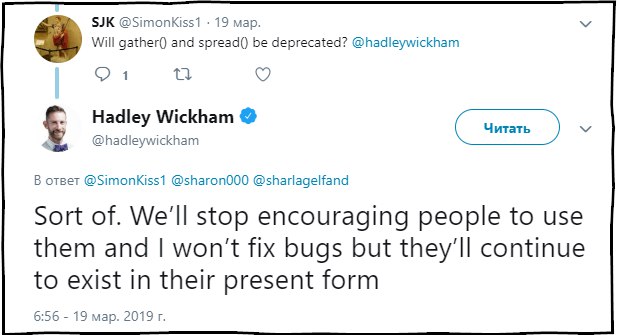
EM
Dmitry Perepechin
Там в вопросе специально указано что это не читшит с рстудио :)
Сорри)
Size: a a a
EM
E
М
М
MP

ДВ
MP
EP
A
> system.time(
+ lc2[,.I[rank==max(rank)],client_code][])
user system elapsed
0.605 0.017 0.637
> system.time(
+ lc2[,.SD[rank==max(rank)],client_code][])
Timing stopped at: 63.17 2.041 66.88
mean(), max() и пр.AK
PU
AK
PU
tg_cols <- payments2[, names(.SD), .SDcols = 1:3]
payments2[, (tg_cols) := lapply(.SD, is.character), .SDcols = tg_cols]
AK
YB
IS
mean(), max() и пр.> system.time(lc2[lc2[,.I[rank==max(rank)],client_code]$V1])
user system elapsed
0.737 0.028 0.779
> system.time(lc2[,.SD[rank==max(rank)],client_code][])
Timing stopped at: 33.32 0.743 34.57
IS
AS
PU
IS
':='