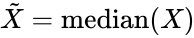А
Спасибо ! А есть ещё варианты? Или релевантные ссылки почитать
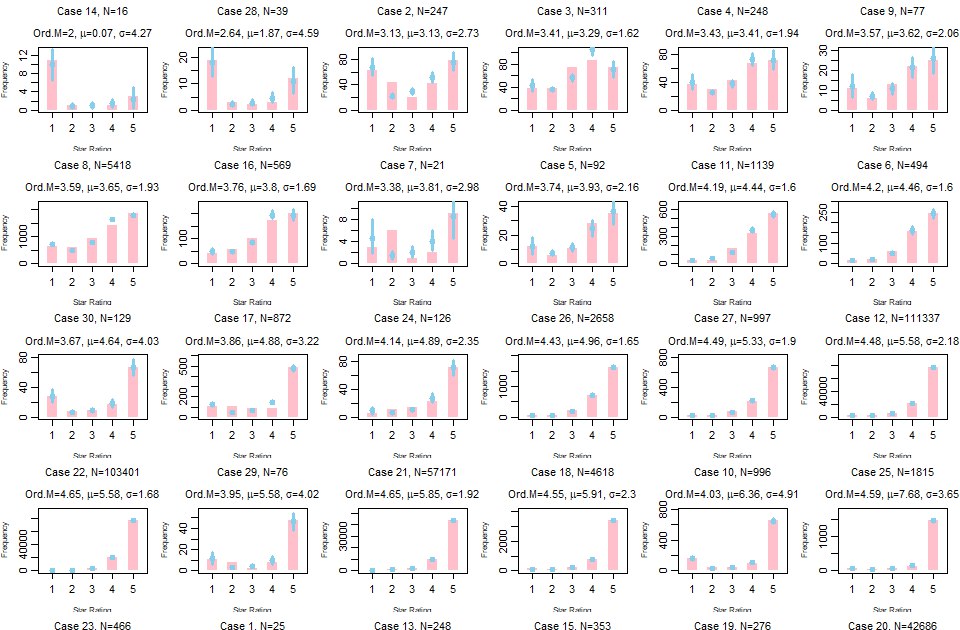
Рейтинг- это же порядковые данные? Вот, попадалось мне случайно. Посмотрите, может что-то подскажет.
https://youtu.be/1-ADJNE1WNc&t=35m20s
https://youtu.be/1-ADJNE1WNc&t=35m20s
Size: a a a
А
A
D
IS
AA
D
ИП
ГД
IS
ГД
ИП
ВК
М
ЕТ
М

М
ЕТ
М
from_1C[, date_1C_load := ymd(date_1C_load)]М