



IS
пример данных нужен
Size: a a a
IS
М
IS
join не считают, насколько мне известно.IS
data.table::getDTthreads() # проверим доступное количество потоков
data.table::setDTthreads(0) # отдаем все ядра в распоряжение data.table
data.table::getDTthreads() # проверим доступное количество потоков
М
h
h
IS
h
IS
h
IS
# генерируем данные на 15 недель
set.seed(42)
events_dt <- tibble(user_id = 1000:9000) %>%
mutate(birthday = Sys.Date() + as.integer(rexp(n(), 1/10))) %>%
rowwise() %>%
mutate(timestamp = list(as_datetime(birthday) + 24*60*60 * (
rexp(10^3, rate = 1/runif(1, 2, 25))))) %>%
ungroup() %>%
unnest(timestamp) %>%
# режем длинные хвосты в прошлом и в будущем
filter(timestamp >= quantile(timestamp, probs = 0.1),
timestamp <= quantile(timestamp, probs = 0.95)) %>%
mutate(date = as_date(timestamp)) %>%
select(user_id, date) %>%
setDT(key = c("user_id", "date")) %>%
# оставим только уникальные по датам события
unique()
# считаем для каждого пользователя "дату рождения"
users_dict <- events_dt[, .(birthday = head(date, 1)), by = user_id]
# а теперь считаем динамику числа уникальных пользователей
users_dict[, .(uN = .N), by = birthday][, cum_uN := cumsum(uN)]
IS
h
IS
survival analysis. Книгу для прикладного примера выше приложил.IS
h
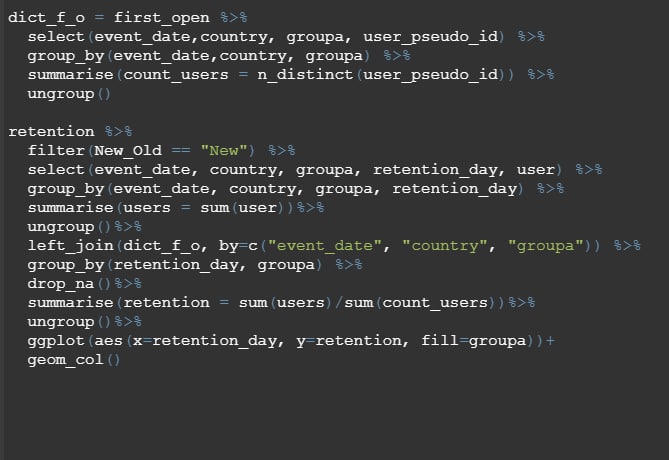
IS
IS
min).setkey делает физическую сортировкуIS
