



A
не, ну если на какой-то ОС
library(data.table) не пишет про потоки, то это можно понятьSize: a a a
A
library(data.table) не пишет про потоки, то это можно понятьДВ
A
R
ДВ
A
ДВ
R
ДВ
R
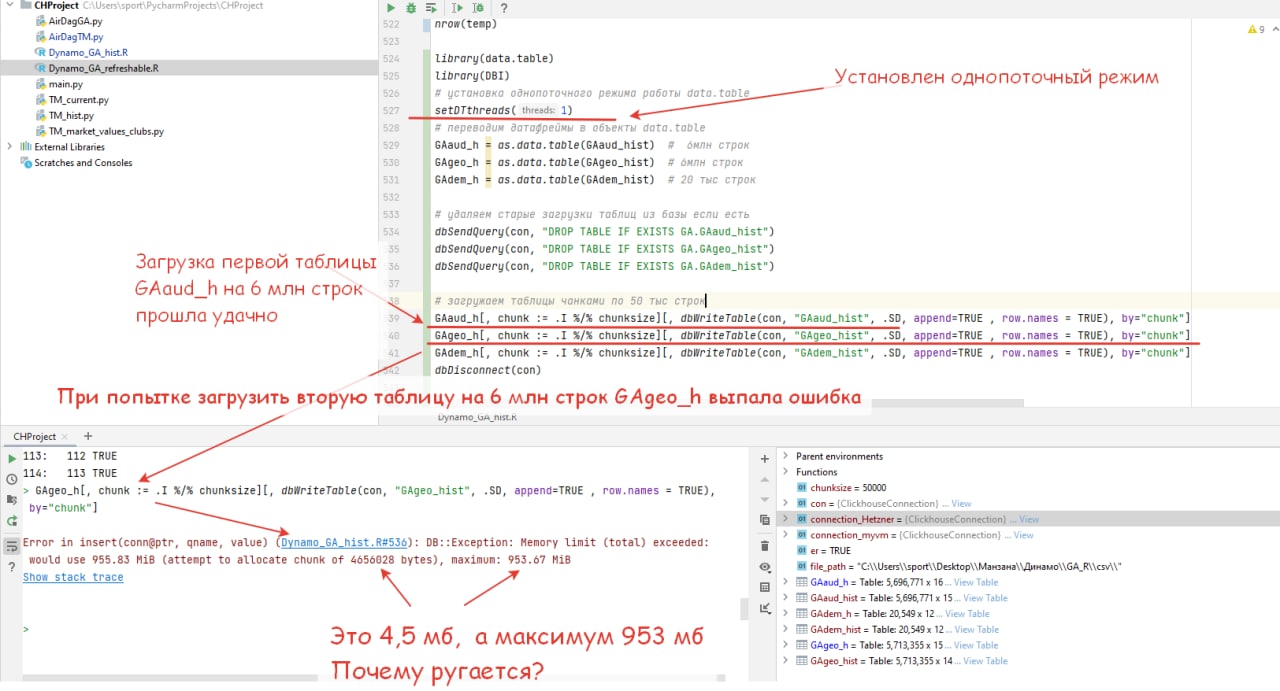
ДВ
ДВ
ДВ
R
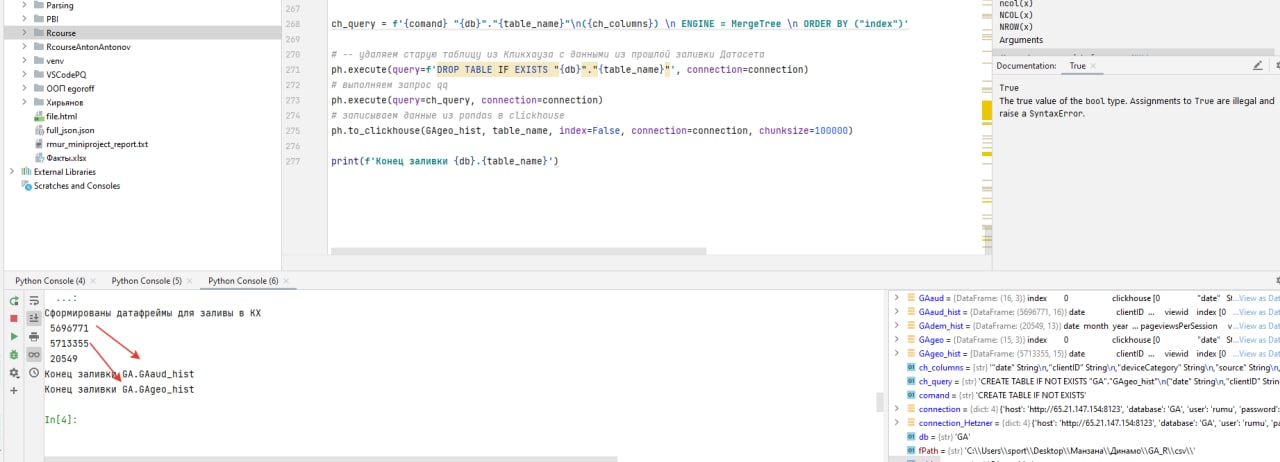
ДВ
ДВ
ДВ
R
R
ДВ