



EP
Ну там же не совсем жуки его переваривают, а микрофлора кишечника их личинок.
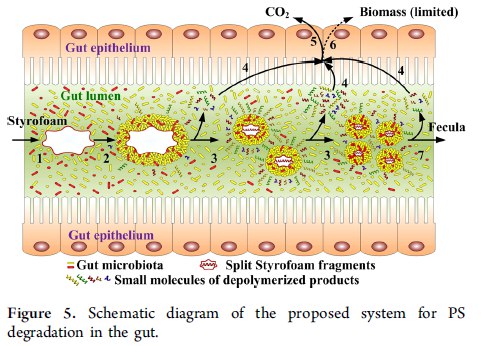
Я походил по ссылкам и нашел работу 2015 года, где как раз анализировались какашки червяков. Вот статья и вот даже картинка есть.
>А во что они его превращают? На простых углеводов, а потом в углекислый газ?
Выходит, что так. Как я понял, там не всё распадается до CO2, что-то просто до более коротких фрагментов. Интересно, можно ли это назвать простыми безвредными углеводами, которе кто-то другой сожрет?
Или же получается, что эти личинки как-то неэкологично утилизируют пластик, если генерят углекислый газ и, оставляют предположительно, микрочастицы. 🤔🤔🤔
Вообще по ходу чтения новостей и статьи не покидало чувство дежавю: как будто в материале про якутских стартаперов просто пересказывался проект каких-то американских школьников.
Я походил по ссылкам и нашел работу 2015 года, где как раз анализировались какашки червяков. Вот статья и вот даже картинка есть.
>А во что они его превращают? На простых углеводов, а потом в углекислый газ?
Выходит, что так. Как я понял, там не всё распадается до CO2, что-то просто до более коротких фрагментов. Интересно, можно ли это назвать простыми безвредными углеводами, которе кто-то другой сожрет?
Или же получается, что эти личинки как-то неэкологично утилизируют пластик, если генерят углекислый газ и, оставляют предположительно, микрочастицы. 🤔🤔🤔
Вообще по ходу чтения новостей и статьи не покидало чувство дежавю: как будто в материале про якутских стартаперов просто пересказывался проект каких-то американских школьников.

