



S
Size: a a a
2020 March 18
ww
я как новый в етой теме, такие запросы ешё не делал, просто в html искал нужное с помощью xpath
RG
wowa wowa
спасибо тебе, ты меня выручил. Мне осталось найти json ответ где всё нужное находится.
для новичка это сложноватая тема. Если нужно быстро сделать, все же используй браузер
ww
вот в данный момент смотрю как ето делается
S
для новичка это сложноватая тема. Если нужно быстро сделать, все же используй браузер
Ну ему надо быстро, а selenium это не быстро
RG
Ну ему надо быстро, а selenium это не быстро
Ну Splash можно. Там ему ведь только страничку чтоб отрендерило и ничего кликать не нужно. Нам ведь Splash можно на докере поднять
S
Ну Splash можно. Там ему ведь только страничку чтоб отрендерило и ничего кликать не нужно. Нам ведь Splash можно на докере поднять
Проще json забрать. Splash в докер, для новичка, совсем мне кажется тяжко
ww
с помощью сплеш я уже смог вычитать некоторые страницы, а ето страница не даёт ответ html
ww
поетому попробую json забрать
2020 March 19
A
Ни у кого нет етой книжки?
A

A
Фулл версион?
ww
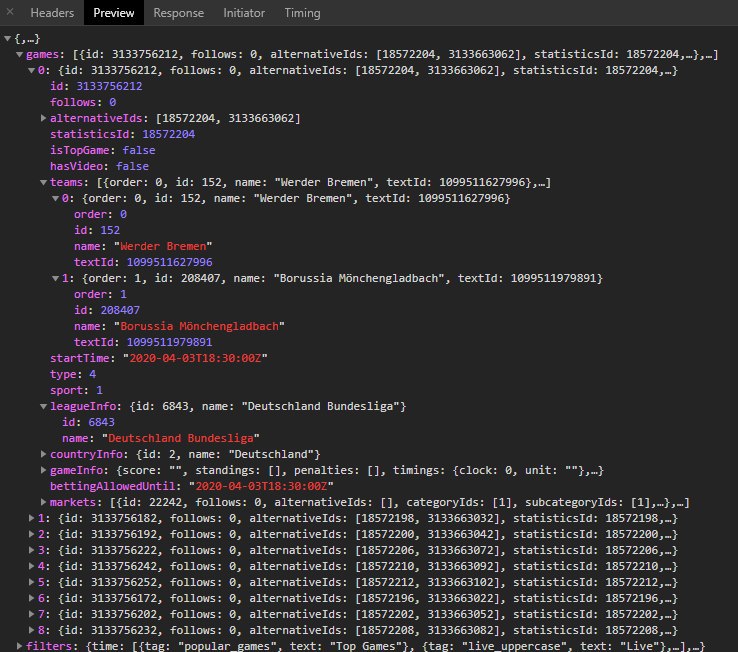
Это SPA. Фронтенд на JS общается с сервером через json. Тебе нужно перехватывать эти запросы и парсить их.
чёта у меня не как не получается достать етот json файл. я его нашёл, скопировал requestheader и поставил в headers моего паука. start_urls у меня сайт который я парсить хочу а url в scrapy.Request() я взял от json файла в котором все данные находятся. что не правилно делаю?
AS
wowa wowa
чёта у меня не как не получается достать етот json файл. я его нашёл, скопировал requestheader и поставил в headers моего паука. start_urls у меня сайт который я парсить хочу а url в scrapy.Request() я взял от json файла в котором все данные находятся. что не правилно делаю?
Просто этот запрос в браузере открой, вернёт json ?
АК

привет, может кто подсказать куда мне нужно копать при этих ошибках, запускаю в контейнере код валится когда пытается открыть url
options = Options()
options.binary = which("firefox")
options.headless = True
_logger.info('Start driver, {}'.format(which("firefox")))
driver = webdriver.Firefox(service_log_path='/opt/selenium/selenium.log', options=options)
_logger.info('Getting URL. {}'.format(url))
driver.get(url)
S
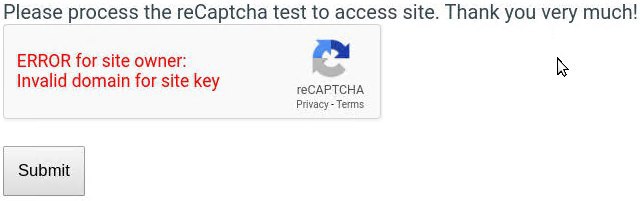
По запросу crawlera гугл предложил рекламу сервиса https://www.scraperapi.com/, который по сути является аналогом краулеры, но за меньшие деньги. Захотел попробовать воспользоваться на сайте, где обычно всплывают капчи после определенного числа запросов с одного адреса. Сделал 10 тестовых запросов, в 4 из которых получил следующий результат:
S
Что это за баг такой с капчей? И почему это может происходить? 🤔