🎱
"все что не убивает, делает нас сильнее"
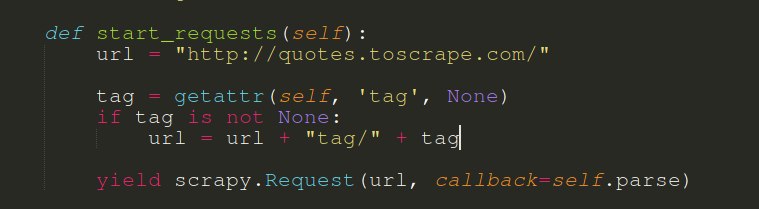
Если сайт даёт (и не банит), и ты можешь прожевать - хоть мульён запрашивай
Если сайт даёт (и не банит), и ты можешь прожевать - хоть мульён запрашивай
сайт дает тянуть столько)
но кажется, это не самая лучшая практика, решил узнать мнение экспертов
но кажется, это не самая лучшая практика, решил узнать мнение экспертов