



A
Size: a a a
2020 June 08
OS
Приветствую всех. Подскажите пожалуйста, есть ли способ запустить паука и не закрывать. Сделать как-то так что бы он делал запрос на урлы, парсил, снова запрос и т.д.
К
Приветствую всех. Подскажите пожалуйста, есть ли способ запустить паука и не закрывать. Сделать как-то так что бы он делал запрос на урлы, парсил, снова запрос и т.д.
Все время добавляй новые запросы
OS
Все время добавляй новые запросы
а как? Он же start_requests запустит и привет
AR
через schedule()
SS
а как добавить ссылку к концу очереди в пауке? start_requests.append() сработает?
AR
и это вроде было в доке прямо отдельным абзацем, но я не уверен
AR
а как добавить ссылку к концу очереди в пауке? start_requests.append() сработает?
через schedule()
@
а как добавить ссылку к концу очереди в пауке? start_requests.append() сработает?
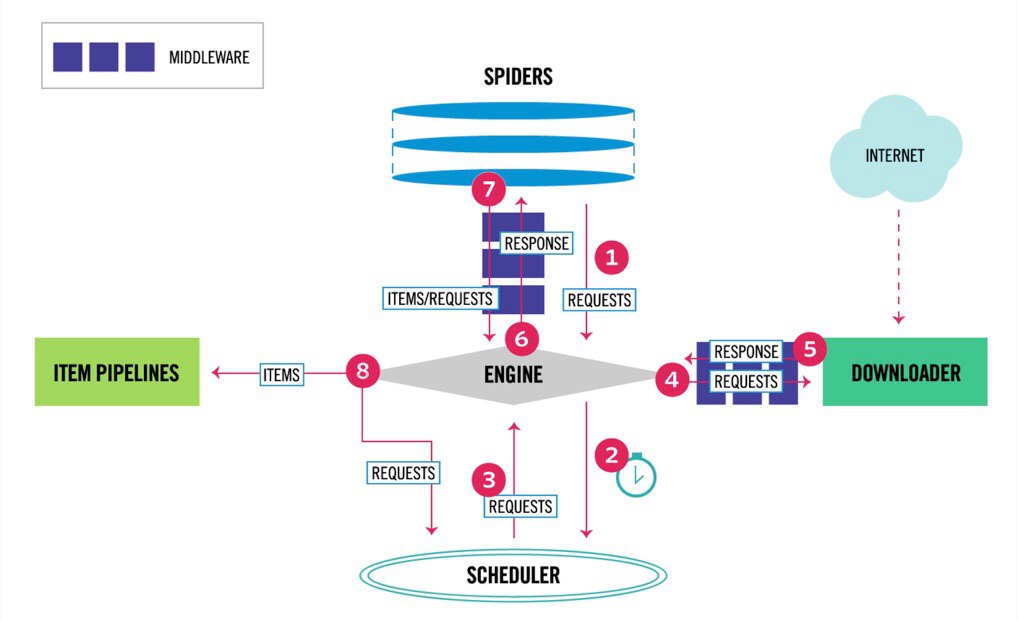
B
ну там же не синхронно ссылки берутся, поэтому если нужно именно самым последним проверить то сувать ему свой idle или spider_close. Но может что-то и есть другое.
A
def __init__(self):
self.profile = webdriver.FirefoxProfile()
self.profile.set_preference("intl.accept_languages", "ua_RU")
self.profile.set_preference("dom.disable_open_during_load", False)
self.fireFoxOptions = webdriver.FirefoxOptions()
self.fireFoxOptions.set_headless()
self.driver = webdriver.Firefox(firefox_profile=self.profile, firefox_options=self.fireFoxOptions)
подскажите правильно ли я описал настройки?вроде все работает но какое то чувство, что где то я накосячил)
AR
вопросы должны были возникнуть когда в логе не обнаружилось Scraped from
AR
дебаж код
🎱
вопросы должны были возникнуть когда в логе не обнаружилось Scraped from
скрейпит всего 137 страниц в конце, а страниц там 22к
AR
до yield item доходит или нет?
🎱
до yield item доходит или нет?
нет, кажется понял в чем дело
AR
а ведь этот вопрос стоило задать себе в первую очередь
🎱
а ведь этот вопрос стоило задать себе в первую очередь
да, не подумал...
спасибо.
спасибо.