



AV
Size: a a a
2020 July 19
B
а при этом visual studio build tools у меня в системе стоят вроде, странно
Создай ишью меинтейнер быстро отвечает.
B
решил json из js вытаскивать, так он там с одинарными ковычками, и json.loads (ну, верней orjson) плачет что не валидный json, я конечно их тупозаменой заменил на двойные, но что если там какие-нибудь эффекты экранирования возникнут(
В SO есть скрипт исправления, вроде даже тут кидал. Если не найдёшь, пингани я поищу.
SS
чтобы паук начал собирать куки с сайтов и отправлять их в следующих запросах достаточно поставить COOKIES_ENABLED=True в настройках?
AR
это и так дефолт
SS
что нужно сделать чтобы ссылки из списка не отправлялись в пайплайн?
AR
это как?
SS
в пауке
custom_settings = {
'ITEM_PIPELINES': {
'sds.pipelines.PdfFilesPipeline': 1
}
}
Есть список ссылок, которые не должны оказаться в PdfFilesPipeline. Как реализовать запрет на обработку этих ссылок пайплайном, желательно без его переписывания?
custom_settings = {
'ITEM_PIPELINES': {
'sds.pipelines.PdfFilesPipeline': 1
}
}
Есть список ссылок, которые не должны оказаться в PdfFilesPipeline. Как реализовать запрет на обработку этих ссылок пайплайном, желательно без его переписывания?
AR
никак
AR
ну т.е. "ссылки" конечно никакие пайплайны не обрабатывают
AR
хотя может на самом деле надо вообще не создавать айтемы с этими ссылками, но про это заказчик умолчал
i
короче, чтобы не выползала первая ошибка надо было обновить build tools с 14.25 до 14.26, а чтобы эта ошибка про io.h не вылезала - надо дополнительно поставить windows 10 sdk там же (в visual studio community installer):
include\pyconfig.h(59): fatal error C1083: ЌҐ г¤ Ґвбп ®вЄалвм д ©« ўЄ«о票Ґ: io.h: No such file or directory,
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\VC\\Tools\\MSVC\\14.26.28801\\bin\\HostX86\\x64\\cl.exe' failed with exit status 2
include\pyconfig.h(59): fatal error C1083: ЌҐ г¤ Ґвбп ®вЄалвм д ©« ўЄ«о票Ґ: io.h: No such file or directory,
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\VC\\Tools\\MSVC\\14.26.28801\\bin\\HostX86\\x64\\cl.exe' failed with exit status 2
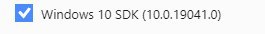
AR
да, быстрее было бы машинный код написать самому
i
В SO есть скрипт исправления, вроде даже тут кидал. Если не найдёшь, пингани я поищу.
да, скинь если найдешь плиз, пригодится в будущем, а то я пока нашел ast.literal.eval, но на моих данных он помирает с ValueError: malformed node or string:
и demjson.decode, но работает по-сравнению с тупо-заменой одинарных на двойные кавычки и затем orjson.loads очень медленно.
и demjson.decode, но работает по-сравнению с тупо-заменой одинарных на двойные кавычки и затем orjson.loads очень медленно.
AR
интересно, в качестве оффтопа, почему на куче сайтов внутри <script> поля в этих json не по-стандарту обвешаны одинарными кавычками
потому что это не json