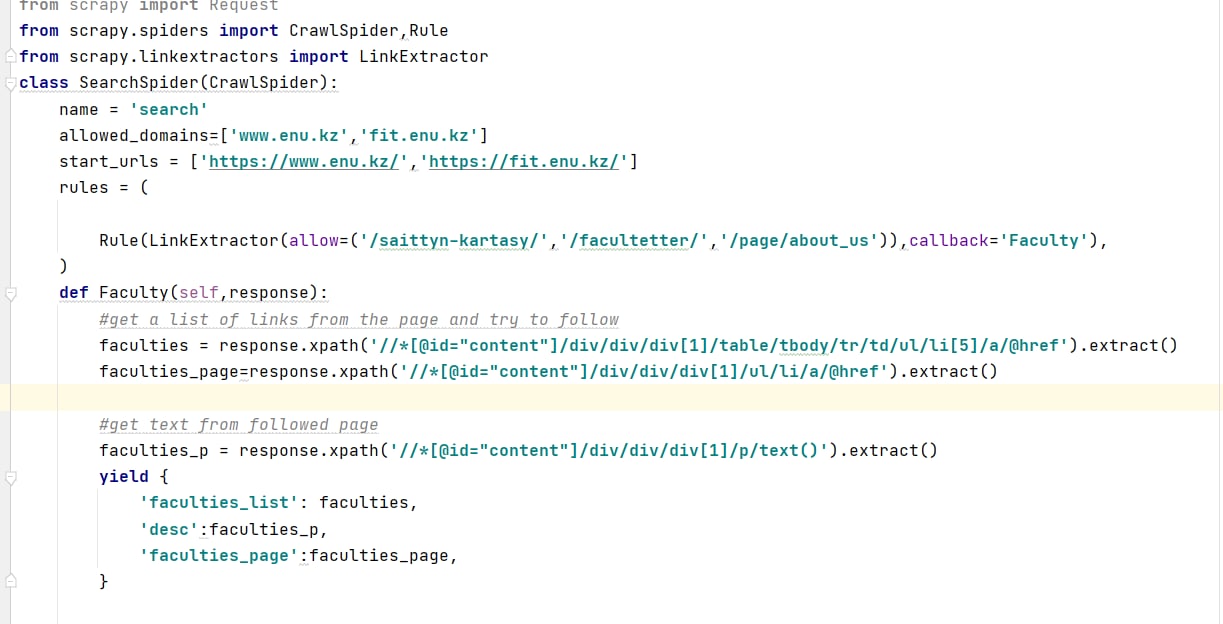
хз я никогда не пользовался linkextractor, мне кажется это не тот случай когда он нужен. не надо пытаться сделать универсальную функцию обработчик, раз у тебя сайты разные то и обработчики отдельно надо
что-то типа
start_urls = ['
enu.kz']
def parse(self, response):
faculty_links = response.xpath(...)
for url in faculty_links:
yield scrapy.Request(url, callback = process_faculty)
def process_faculty(self, response):
do_smth
ну общая схема такая а там смотри по ситуации смотря что тебе в итоге надо, если надо зайти на определенную страницу на сайте факультета то соответственно делаешь отдельный обработчик для этой страницы