



П
Size: a a a
2021 February 04
МС
Вот start_requests метод, он же запускается после инициализации паука ?
да. Есть два взаимозаменяющих варианта задания стартовых адресов:
1. использовать свойство start_urls
2. использовать метод start_requests
1. использовать свойство start_urls
2. использовать метод start_requests
МС
брр, ты хочешь знать это относительно инициализации и деструктора?
OS
В доках написано что при закрытии и открытии паука. Вот только когда они закрываются, открываются :D
МС
ага, только там не расписано когда сигналы срабатывают 😂
МС
open_spider и close_spider когда отрабатывают?
ну, я точно знаю что в сигнале close_spider паука не получается поднять :))
S
У меня вообще 2 варианта в голове.
Первый это использовать inmemory хранилище типа redis, импортировать туда все записи, и по 1 доставать. Но тогда теряется отказоустойчивость.
Второй, это брать по 100 записей, менять статус на running, вытащить данные, поставить complete. В случае закрытия паука я потом продолжу с того-же места
Первый это использовать inmemory хранилище типа redis, импортировать туда все записи, и по 1 доставать. Но тогда теряется отказоустойчивость.
Второй, это брать по 100 записей, менять статус на running, вытащить данные, поставить complete. В случае закрытия паука я потом продолжу с того-же места
Примерно такая же задача стоит. Но я планировал через редис с двумя базами решать. База с урлами вся и база с куда ложить пройденные урлы
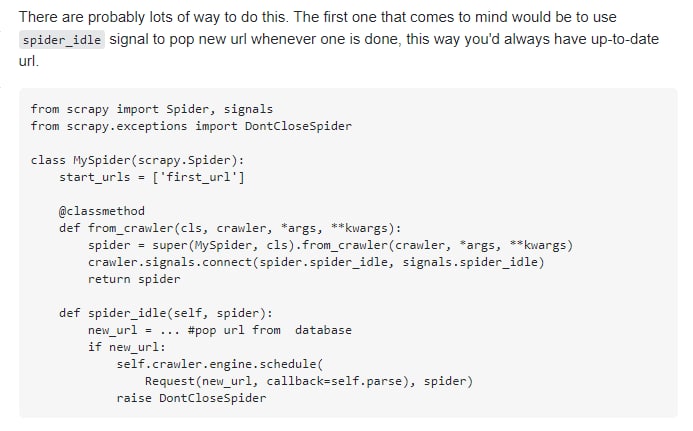
К
У меня вообще 2 варианта в голове.
Первый это использовать inmemory хранилище типа redis, импортировать туда все записи, и по 1 доставать. Но тогда теряется отказоустойчивость.
Второй, это брать по 100 записей, менять статус на running, вытащить данные, поставить complete. В случае закрытия паука я потом продолжу с того-же места
Первый это использовать inmemory хранилище типа redis, импортировать туда все записи, и по 1 доставать. Но тогда теряется отказоустойчивость.
Второй, это брать по 100 записей, менять статус на running, вытащить данные, поставить complete. В случае закрытия паука я потом продолжу с того-же места
Не надо ин мемори, 7кк это достаточно много для оперативки. Рэдис умеет и на жесткий диск сбрасывать для стабильности, но не надо с этим морочиться, лучше обычную бд
МС
1. spider_idle забирает 100 записей из бд, меняет статус на proccess
2. Pipeline по завершению работы по урлу меняет статус на complete
Верно ?
2. Pipeline по завершению работы по урлу меняет статус на complete
Верно ?
1. какое "по завершению работы", может по размеру пула?
2. бери больше 100 (ну, кроме стадии отладки), хотя бы 1000 записей. По ощущениям, spider_idle возникает когда скачана и обработана последняя ссылка. Скорость, при размере блока 100 ссылок, сильно пострадает. Я бы, на 7кк вообще тысяч по 50-100 забирал
2. бери больше 100 (ну, кроме стадии отладки), хотя бы 1000 записей. По ощущениям, spider_idle возникает когда скачана и обработана последняя ссылка. Скорость, при размере блока 100 ссылок, сильно пострадает. Я бы, на 7кк вообще тысяч по 50-100 забирал
П
1. какое "по завершению работы", может по размеру пула?
2. бери больше 100 (ну, кроме стадии отладки), хотя бы 1000 записей. По ощущениям, spider_idle возникает когда скачана и обработана последняя ссылка. Скорость, при размере блока 100 ссылок, сильно пострадает. Я бы, на 7кк вообще тысяч по 50-100 забирал
2. бери больше 100 (ну, кроме стадии отладки), хотя бы 1000 записей. По ощущениям, spider_idle возникает когда скачана и обработана последняя ссылка. Скорость, при размере блока 100 ссылок, сильно пострадает. Я бы, на 7кк вообще тысяч по 50-100 забирал
У меня примерно 7кк ссылок в базе. Приму к сведению, спасибо!