G
в условии такой пунктик:
Make use of the Scrapy settings to limit the number of items crawled to 100
Make use of the Scrapy settings to limit the number of items crawled to 100
Size: a a a
G
AR
AR
G
closespider extension, который обрабатывает CLOSESPIDER_TIMEOUT, CLOSESPIDER_ITEMCOUNT, CLOSESPIDER_PAGECOUNT, CLOSESPIDER_ERRORCOUNT - работает немного иначе.AB
CLOSESPIDER_ITEMCOUNT = 100
все равно скрапится больше 100. (116)AR
Z
class IconsPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None, *, item=None):
path = '/'
if item:
adapter = ItemAdapter(item)
ext_id = str(adapter['ext_id'])
folder = Path(info.spider.name, ext_id)
path = (folder / request.url.split('/')[-1]).as_posix()
else:
logger.error('ITEM MISSED')
logger.info(path)
return path
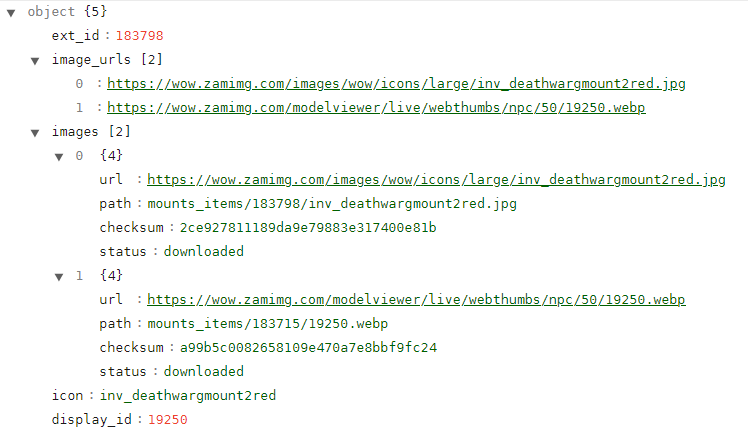
А на изображении айтем с загруженными картинками.К
class IconsPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None, *, item=None):
path = '/'
if item:
adapter = ItemAdapter(item)
ext_id = str(adapter['ext_id'])
folder = Path(info.spider.name, ext_id)
path = (folder / request.url.split('/')[-1]).as_posix()
else:
logger.error('ITEM MISSED')
logger.info(path)
return path
А на изображении айтем с загруженными картинками.BL
МС
МС
GB
МС
GB
AS
S
AS