Screaming Frog SEO Spider обновился до 11 версии.Обновлений не такие крутые, как в 10 версии, но они есть. Сейчас расскажу, что обновилось.
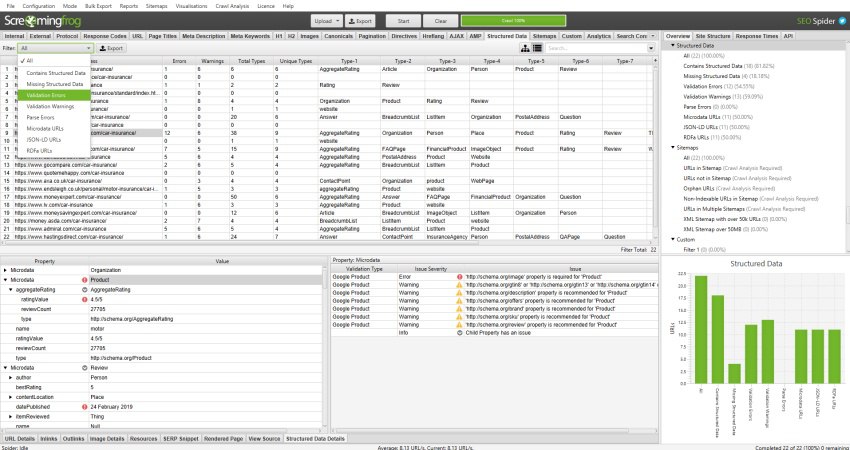
Структурированные данные и их валидацияТеперь можно парсить разметку форматов: JSON-D, Microdata (она же микроразметка), RDFa и
Schema.org. Парсить можно было и раньше с помощью Custom Exptraction, но теперь еще можно и валидировать это всё.
Кроме этого можно сделать массовый отчет по извлеченным данным разметки (Reports -> Structure Data)
Мультивыбор данных и массовый экспортНу это вот прям стырено у Нетпика. Раньше можно было анализировать входящие ссылки только у одного урла в интерфейсе, либо выгрузить большой отчет по всем входящим и уже его фильтровать в Excel'е. Теперь вы можете выбрать произвольное количество урлов в отчете и выгрузить входящие ссылки на эти урлы. Очень удобно, хотя в нетпике это делается еще проще - в одно нажатие клавиши.
Экспорт древовидного отчетаОпять же повторение фичи нетпик спайдера. Все отчеты раньше выгружались только в виде списка урлов. Разбить по папочкам это дело было невозможно. Теперь вы можете выгрузить в виде дерева в таблицу, чтобы потом можно было проще фильтровать и анализировать отчет.
Улучшили визуализацию графов🔸Теперь можно выбирать из какого поля брать подписи вершин: url, title, h1 или h2. Выбор небогатый, но всяко лучше, чем по урлам ориентироваться
🔸Сделали возможность поиска нужной вершины (т.е. страницы) в графе, а не просто фильтрацию. Можно увидеть эту вершину на полном графе, а не часть графа с этой вершинкой. Удобненько.
Умный Drag&DropНу это чисто для удобства - можно перетаскивать любые файлы, которые поддерживаются в лягушке в интерфейс и они открываются или импортируются. В нетпике эта функция тоже давно работает.
Экспорт очереди сканированияОчень удобно, если вы сканируете большой проект и вам некогда дожидаться окончания скана, то можно не просто сохранить проект, но и выгрузить очередь скана. И скажем перекинуть эту очередь в нетпик спайдер, где такая функция работает с декабря 2018 года. Ну и он не жрет столько памяти, как современная лягушка. (да, мне очень зашел новый спайдер)
Матчинг расширенных урлов в GA с реальнымиЕсли у вас в проект подключён GA, в котором настроено изменение/расширение урла (есть такая фича у аналитикса, кто не знал), то матчить данные с реальными урлами раньше было нельзя. А теперь вот можно и это будет все нормально импортироваться в проект.
Есть еще мелкие изменения в интерфейсе, которые можно просто перечислить
🔸Вкладки
URL Info и
Image Info переименовали в
URL Details и
Image Details.
🔸Опция
Auto Discover XML Sitemaps via robots.txt автоматически отлючается в List Mode
🔸Новая опция
Max Links per URL to Crawl доступна в конфиге
Config > Spider > Limitsи максималка 10 000.
🔸Еще одна опция в конфиге
Max Page Size (KB) to Crawl. Найти можно там же
Config > Spider > Limits, максималка 50 000.
🔸Раскидали подсказки по интерфейсу, чтобы вам проще было найти нужные опции в конфигах.
🔸Обновился HTML parser, чтоб пофиксить баг с незакавыченными каноникалами.
🔸Пофиксили баг, из-за которого цели в GA могли не отображаться в отчетах.
Так же почитайте оригинальный пост в блоге лягушки: http://seoch.at/uh76lV/Обновляться можно здесь: http://seoch.at/uh76lw/